什么是数据库索引?
数据库的索引:为了使得查询数据的效率变快。(1)聚集索引(主键索引):在数据库里面,所有的行数都会按照主键索引进行排序。(2)非聚集索引:给普通的字段加上索引。(3)联合索引(多属性索引):给好几个字段加上索引。联合索引的时候怎么走?where age = '18' and name = '小张'and sex = '男' 这种格式的,所以还是走索引,遵循最左匹配的原则。(4)对于D,因为age>
索引的作用
数据库的索引:为了使得查询数据的效率变快。
数据库索引有哪些
(1)聚集索引(主键索引):在数据库里面,所有的行数都会按照主键索引进行排序。
(2)非聚集索引:给普通的字段加上索引。
(3)联合索引(多属性索引):给好几个字段加上索引。
联合索引的时候怎么走?
key 'idx_age_name_sex' ('age','name','sex')A:select * from student where age = 16 and name = '小张'
B:select * from student where name = '小张' and sex = '男'
C:select * from student where name = '小张' and sex = '男' and age = 18
D:select * from student where age > 20 and name = '小张'
E:select * from student where age != 15 and name = '小张'
F:select * from student where age = 15 and name != '小张'
(1)对于A,遵循最左匹配,age在最左边,所以A走索引。
(2)对于B,直接从name开始,不遵循最左匹配的原则,所以不走索引使得。
(3)对于C,虽然是从name开始,但是又索引最左边的age,内部会转成
where age = '18' and name = '小张' and sex = '男'
这种格式的,所以还是走索引,遵循最左匹配的原则。
(4)对于D,因为age>20是范围,范围字段会结束索引对范围后面索引字段的使用,所以只走了age这个索引。
(5)对于E,虽然遵循最左匹配但是是!=,不走索引。!=不走索引。
(6)对于F,只走age索引,不走name索引,原因和(5)一样,!=不走索引。
什么样的情况不走索引
如果在表student中两个字段age,name加了索引
key 'idx_age' ('age'),
key 'idx_name' ('name')1.Like这种就是%在前面的不走索引,在后面的走索引。
A:select * from student where 'name' like '王%'
B:select * from student where 'name' like '%小'A走索引,B不走索引。
2.用索引列进行计算的,不走索引。
A:select * from student where age = 10+8
B:select * from student where age + 8 = 18A走索引,B不走索引。
3.对索引列用函数的时候,不走索引。
A:select * from student where concat('name','哈') ='王哈哈';
B:select * from student where name = concat('王哈','哈');A不走索引,B走索引
4.索引列用了!=的时候,不走索引:
select * from student where age != 18索引在磁盘上是怎么存储的?
聚类索引和非据类索引的存储是不同的。
有一张学生表:
create table `student` (
`id` int(11) not null auto_increment comment '主键id',
`name` varchar(50) not null default '' comment '学生姓名',
`age` int(11) not null default 0 comment '学生年龄',
primary key (`id`),
key `idx_age` (`age`),
key `idx_name` (`name`)
) ENGINE=InnoDB default charset=utf8 comment ='学生信息';
表中的内容如下:

id 为主键索引,name和age为非聚集索引。
1.聚类索引在磁盘中的存储
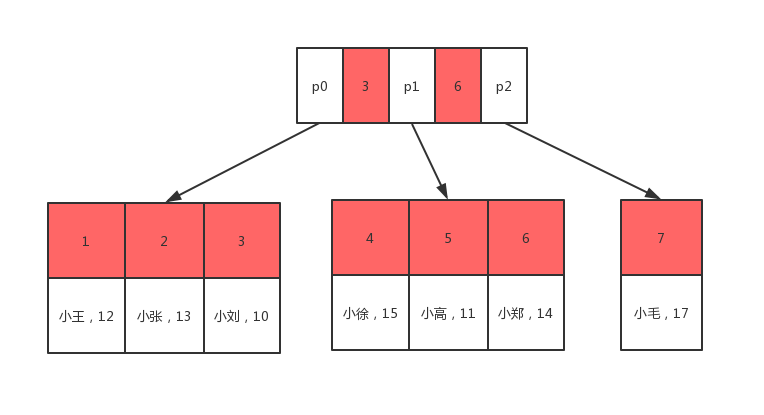
聚类索引叶子节点存储的是表里面所有的行数据,每个数据页在不同的磁盘上。如果要查找id=5的数据,需要先把磁盘0读入内存,然后用二分法查找id=5的树在3和6之间,然后通过指针p1查找到磁盘2的地址,然后将磁盘2读入内存中,用二分查找方式查找到id=5的数据。
2.非聚集索引在磁盘中的存储

叶子结点存储的是据集索引键,而不存储表里面所有的行数据,所以在查找的时候,只能找到聚集索引键,再通过据集索引去表里面查找到数据。
如果要查找到name=小徐,首先将磁盘0加载到内存中,然后用二分查找的方法查找到在指针p1所指的地址上,然后通过指针p1所指的地址可以知道在磁盘2上面,然后通过二分查找法得知小徐的id=4。
然后再继续根据id=4,将磁盘0加载到内存中,然后通过二分查找发查找到在指针p1所指的地址上,然后通过指针p1所指的地址可以知道在磁盘2上面,通过id=4查找到所在行数据,就能查找到name=小徐的数据了。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)