HIVE的三种建表方式
目录一、直接建表二、as (直接使用查询结果插入到一张新表)三、like(复制表结构)一、直接建表中括号里面的均为可选项CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED
·
一、直接建表
中括号里面的均为可选项
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
1.CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常
2.EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
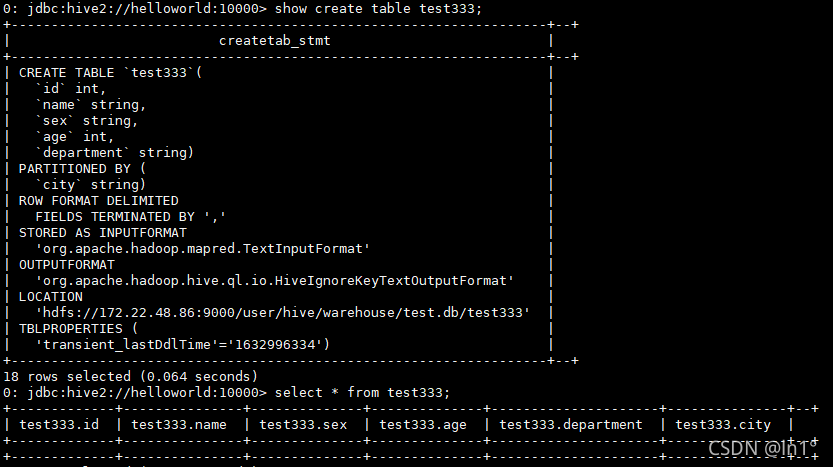
3.LIKE 允许用户复制现有的表结构,但是不复制数据
4.COMMENT 可以为表与字段增加描述
5.PARTITIONED BY 指定分区
6.ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe;
7.STORED AS
SEQUENCEFILE //序列化文件
| TEXTFILE //普通的文本文件格式
| RCFILE //行列存储相结合的文件
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname //自定义文件格式
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE
8.LOCATION 指定表在HDFS的存储路径(默认地址/user/hive/warehouse)
二、as (直接使用查询结果插入到一张新表)
as将查询字段以及结果作为一张新表;
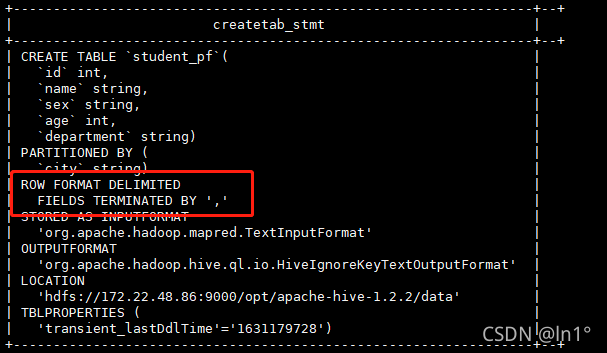
使用as创建的表,原表的分区,以及字段的约束等都会丢失(可以通过describe formatted查看);
新表中会将原表的分区当做字段出现在新表中;
1.将分区表的查询结果作为一张新表:
create table test222 as select * from student_pf where city=‘nanjing’;
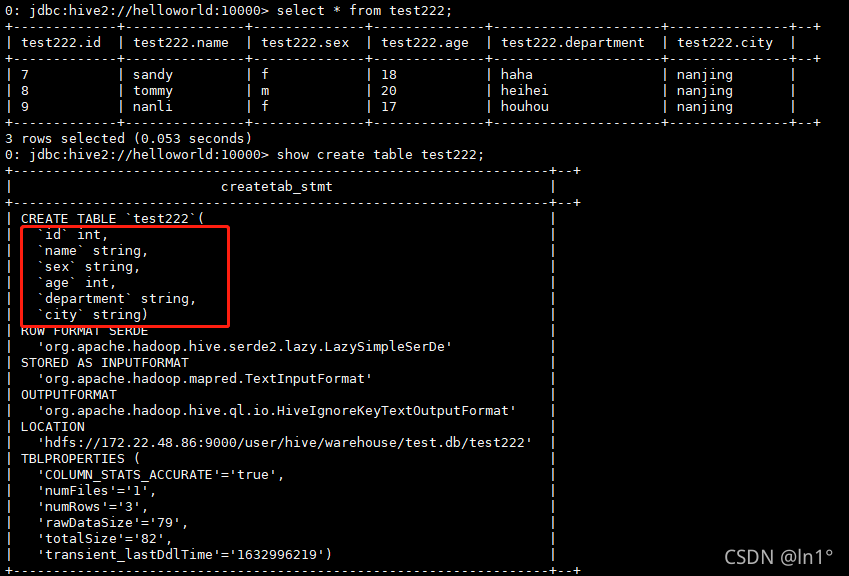
2.as并没有把分隔符复制过来,只复制了查询的字段和字段对应的值:
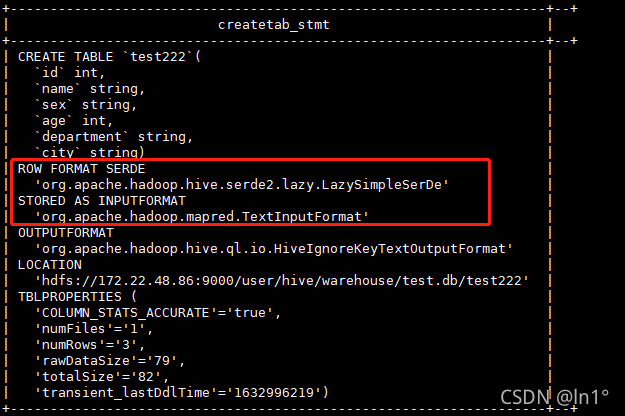
三、like(复制表结构)
create table test333 like student_pf;

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)