记一次k8s集群表征6443:connect refused,无法使用kubectl get pod的问题解决
集群概况(就一个master节点):master 192.168.1.1发现问题:(在一个看似平凡的上午,突然集群出现了这样反应)发现问题后的一个思路:步骤:开始查看防火墙的6443是否打开,(需要打开—zone=internal方向的防火墙),检查后没问题。swap是否关闭。关闭方式:①注释 /etc/fstab 的swap注释(永久关闭swap)。②swappoff -a (暂时关闭swap)
集群概况(就一个master节点):
master 192.168.1.1
发现问题:(在一个看似平凡的上午,突然集群出现了这样反应)

发现问题后的一个思路:
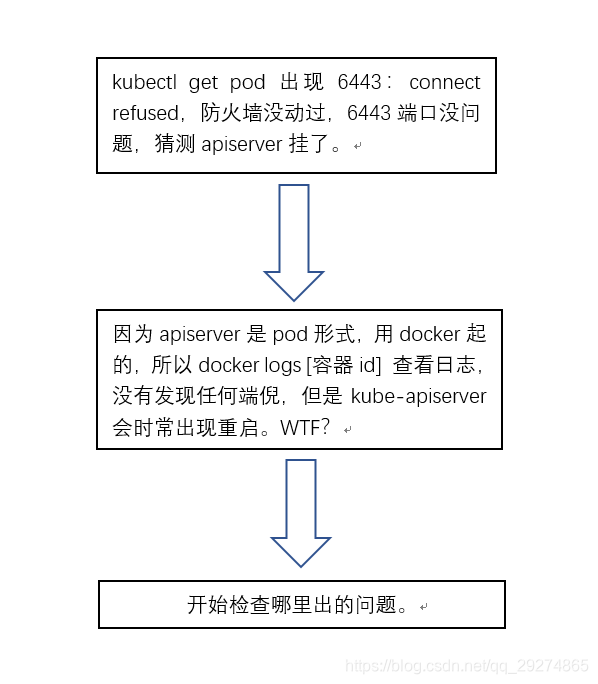
步骤:
- 开始查看防火墙的6443是否打开,(需要打开—zone=internal方向的防火墙),检查后没问题。
- swap是否关闭,本集群检查后没问题。
关闭方式:
① 注释 /etc/fstab 的swap注释(永久关闭swap)。
② swappoff -a (暂时关闭swap)。
③ 查看是否关闭 free -m
[root@km1 ~]# free -m
total used free shared buff/cache available
Mem: 257117 8944 239641 20 8530 247290
Swap: 0 0 0
swap现在是关闭了。
3.既然kube-apiserver经常重启,logs又看不出什么异常,是否是docker本身的问题,查看docker的/etc/docker/daemon.json发现这条“native.cgroupdriver=systemd”没有了,加上它:
{
"registry-mirrors": [
"https://dockerhub.azk8s.cn",
"https://reg-mirror.qiniu.com",
"https://quay-mirror.qiniu.com"
],
"exec-opts": [ "native.cgroupdriver=systemd" ]
}
然后重启docker:
systemctl daemon-reload //重新加载docker服务的配置文件
systemctl restart docker //重启docker
哦吼!失败!重启失败!好吧,看来docker有问题,重装!(我承认我的方法比较低端,哈哈哈)
重装之路:
①我们安装k8s是1.18.0所以通过查询其配套的docker版本是
k8s-1.18对应docker版本 1.13.1, 17.03, 17.06, 17.09, 18.06, 18.09
我们安装18.09版本。
安装命令:
yum install -y docker-ce-18.09.9 docker-ce-cli-18.09.9 containerd.io
设置阿里源:
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
设置/etc/docker/daemon.json,修改cgroupdriver:
{
"registry-mirrors": [
"https://dockerhub.azk8s.cn",
"https://reg-mirror.qiniu.com",
"https://quay-mirror.qiniu.com"
],
"exec-opts": [ "native.cgroupdriver=systemd" ]
}
重启docker:
systemctl daemon-reload //重新加载docker服务的配置文件
systemctl restart docker //重启docker
然后就可以通过docker info | grep Cgroup来查看修改后的 docker cgroup 状态,发现变为systemd即为修改成功。
4.用journalctl -fu kubelet查看kubelet的日志,会发现大量的这样报错:
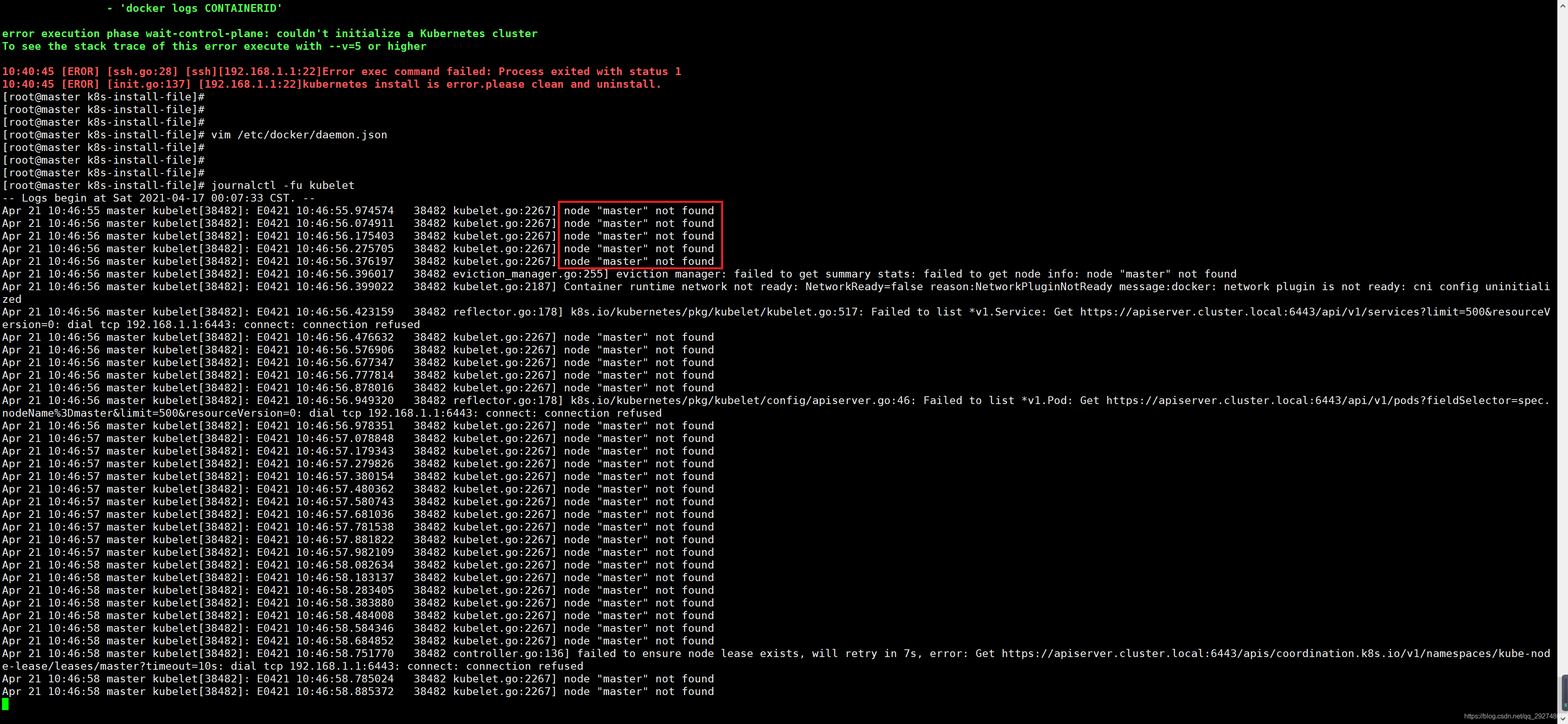
node master 找不到?WTF?就一个节点还有这幺蛾子?防火墙还防自己?索性直接iptables -F刷了iptables规则(要非常小心执行这个,最好先备份,因为我是测试节点,而且就一个节点,刷也就刷了),还是不行!WTF?难道?难道是?对!去看/etc/hosts文件:
果然有一些端倪,大家上眼:
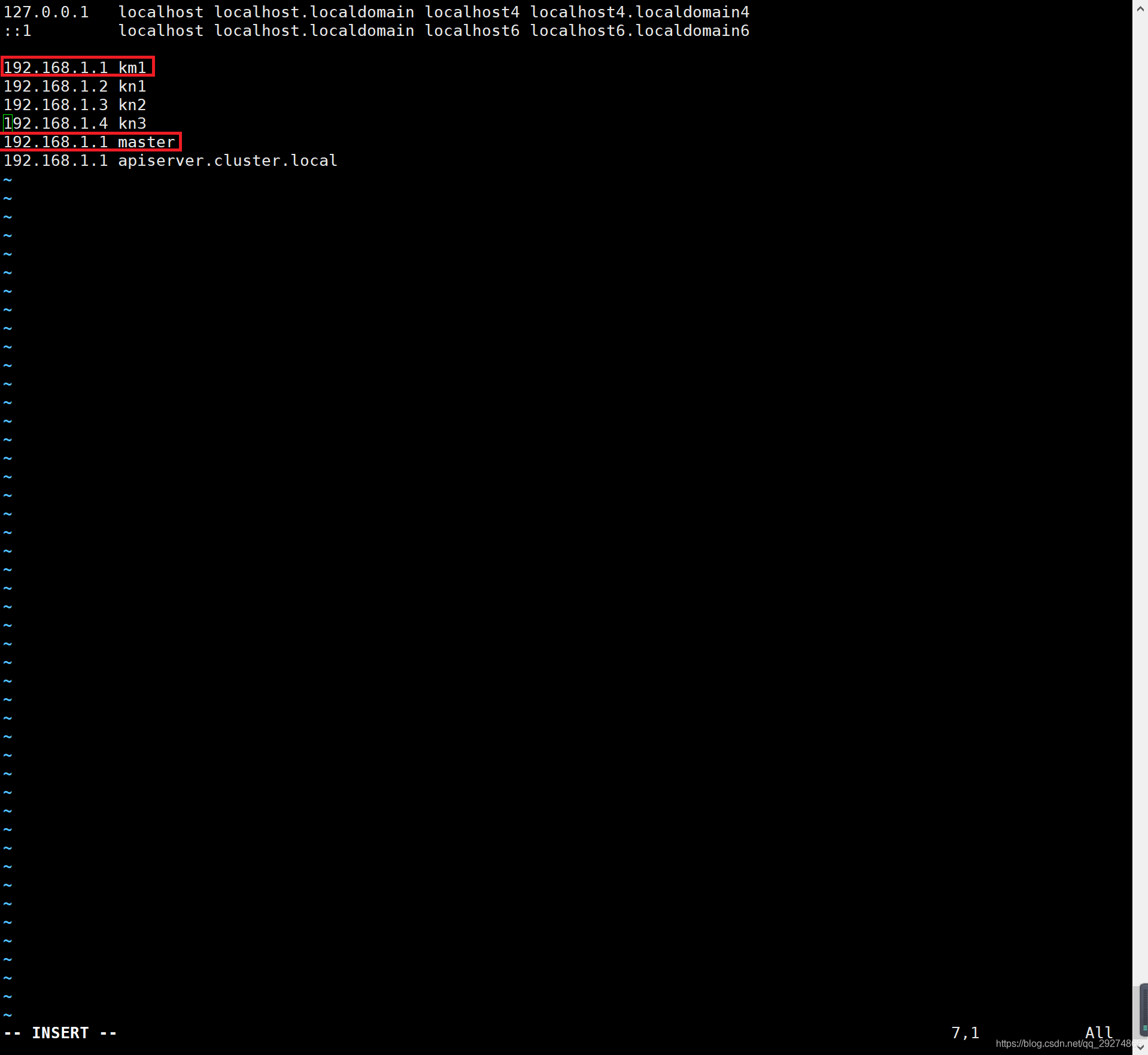
有可能是对192.168.1.1的双重定义导致的无法找到master节点,我们作以下处理,注释掉192.168.1.1 km1的字段:
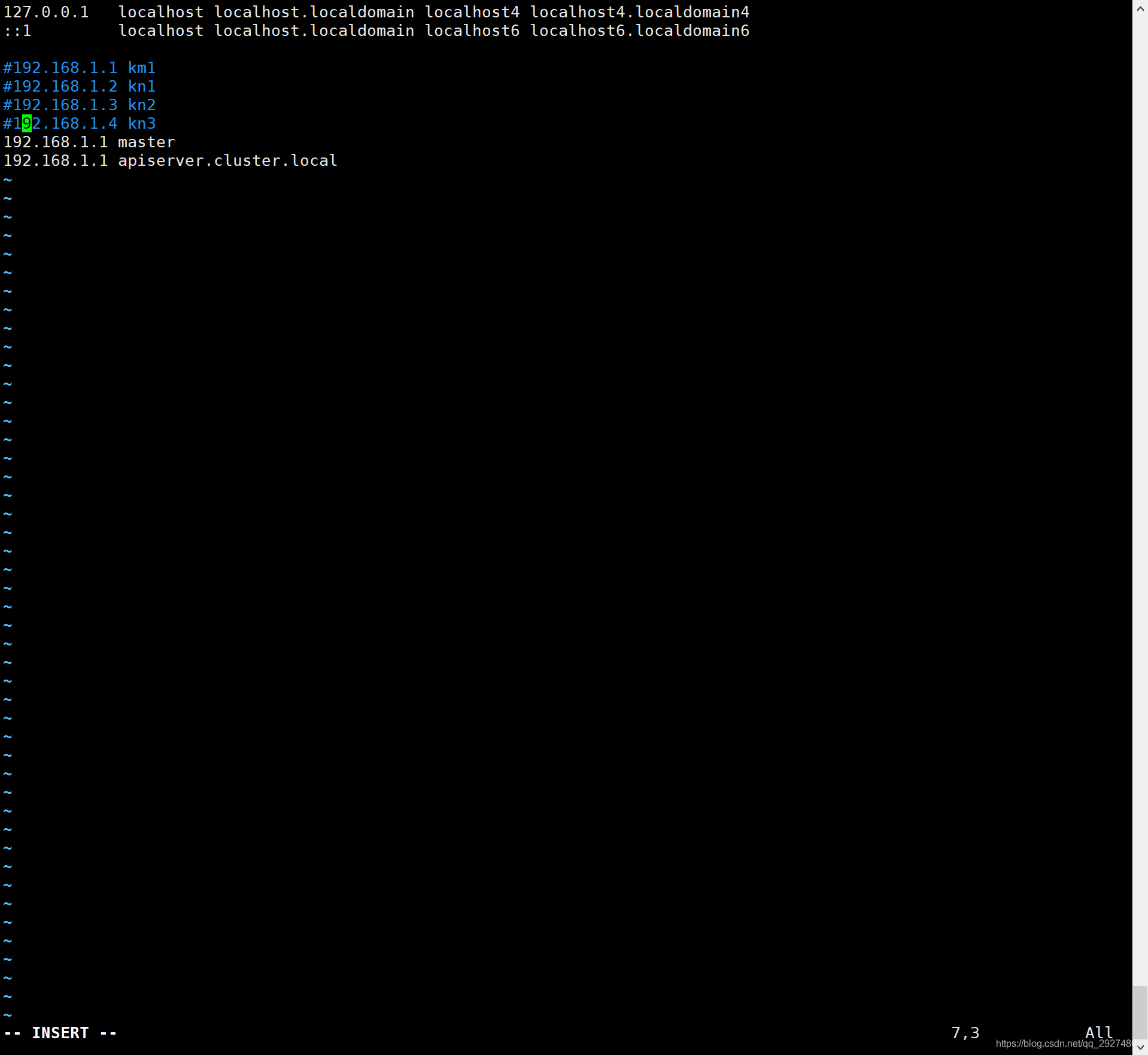
保存退出,然后
reboot
一定要reboot,哈哈哈哈哈
一定要记得
reboot
reboot
reboot
最后,成功!!!Got it!
总结
排查思路:
①防火墙端口。
②swap关闭。
③docker是否正常cgroupdriver=systemd。
④修改了/etc/hosts文件。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)