Docker容器之Docker Swarm集群详解(上)
Swarm是Docker公司自己发布的一套用来管理Docker集群的平台,几乎全部用GO语言来完成的开发,可以在多台机器上对容器进行管理和编排。(Cluster : 集群)Docker Swarm 和 Docker Compose 一样,都是Docker官方容器编排项目,但不同的是,Docker Compose 是一个在单个服务器或主机上创建多个容器的工具,而 Docker Swarm 则可以在多
目录
Swarm介绍
Swarm是Docker公司自己发布的一套用来管理Docker集群的平台,几乎全部用GO语言来完成的开发,可以在多台机器上对容器进行管理和编排。(Cluster : 集群)
Docker Swarm 和 Docker Compose 一样,都是Docker官方容器编排项目,但不同的是,Docker Compose 是一个在单个服务器或主机上创建多个容器的工具,而 Docker Swarm 则可以在多个服务器或主机上创建容器集群服务,对于微服务的部署,显然 Docker Swarm 会更加适合。
Swarm的几个关键概念
Swarm
集群的管理和编排是使用嵌入docker引擎的SwarmKit,可以在docker初始化时启动swarm模式或者加入已存在的swarm。
docker swarm:集群管理,子命令有init, join, leave, update
Node
node是加入到swarm集群中的一个docker引擎实体,可以在一台物理机上运行多个node。
manager节点还执行维护所需群集状态所需的编排和集群管理功能,manager节点选择单个领导者来执行编排任务,worker节点接收并执行从管理器节点分派的任务。
docker node:节点管理,子命令有accept, promote, demote, inspect, update, tasks, ls, rm
Service
一个服务是任务的定义,管理机或工作节点上执行。它是群体系统的中心结构,是用户与群体交互的主要根源。
创建服务时,你需要指定要使用的容器镜像。
docker service:服务创建,子命令有create, inspect, update, remove, tasks
Task
任务是在docker容器中执行的命令,manager节点根据指定数量的任务副本分配任务给worker节点。
Swarm的调度策略
Swarm在调度节点(leader节点)运行容器的时候,会根据指定的策略来计算最适合运行容器的节点。
目前支持的策略有:random,spread,binpack
Random
顾名思义,就是随机选择一个Node来运行容器,一般用作调试用,spread和binpack策略会根据各个节点的可用的CPU, RAM以及正在运行的容器的数量来计算应该运行容器的节点。
Spread
在同等条件下,Spread策略会选择运行容器最少的那台节点来运行新的容器,binpack策略会选择运行容器最集中的那台机器来运行新的节点。
使用Spread策略会使得容器会均衡的分布在集群中的各个节点上运行,一旦一个节点挂掉了只会损失少部分的容器。
Binpack
Binpack策略最大化的避免容器碎片化,就是说binpack策略尽可能的把还未使用的节点留给需要更大空间的容器运行,尽可能的把容器运行在一个节点上面。
Swarm Cluster模式的特点
批量创建服务
建立容器之前先创建一个overlay的网络,用来保证在不同主机上的容器网络互通的网络模式。
强大的集群的容错性
当容器副本中的其中某一个或某几个节点宕机后,cluster会根据自己的服务注册发现机制,以及之前设定的值 --replicas n,在集群中剩余的空闲节点上,重新拉起容器副本。
docker service其实不仅仅是批量启动服务这么简单,而是在集群中定义了一种状态。Cluster会持续检测服务的健康状态并维护集群的高可用性。
服务节点的可扩展性
Swarm Cluster不光只是提供了优秀的高可用性,同时也提供了节点弹性扩展或缩减的功能。当容器组想动态扩展时,只需通过scale参数即可复制出新的副本出来。
调度机制
所谓的调度其主要功能是cluster的server端去选择在哪个服务器节点上创建并启动一个容器实例的动作。
Swarm集群部署
机器环境
| IP | 主机名 | 担任角色 |
| 192.168.58.151 | manager | swarm manager |
| 192.168.58.152 | worker1 | swarm worker |
| 192.168.58.153 | worker2 | swarm worker |
准备工作
1、修改主机名
hostnamectl set-hostname manager
hostnamectl set-hostname worker1
hostnamectl set-hostname worker22、配置hosts文件
[root@manager ~]# vim /etc/hosts
# 在文件末尾添加以下三行
192.168.58.151 manager
192.168.58.152 worker1
192.168.58.153 worker2
# 使用scp复制到所有机器
[root@manager ~]# scp /etc/hosts root@192.168.58.152:/etc/hosts
[root@manager ~]# scp /etc/hosts root@192.168.58.153:/etc/hosts3、关闭防火墙
# 关闭三台机器上的防火墙
systemctl stop firewalld
systemctl disable firewalld4、安装docker
1.卸载旧的版本
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
2.需要的安装包
yum install yum-utils -y
3.设置镜像的仓库
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo # 默认是国外的
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # 建议安装国内的
4.安装docker ——Install Docker Engine
# docker-ce 社区版 docker-ee 企业版
yum install docker-ce docker-ce-cli containerd.io -y
5.启动docker
systemctl start docker
6.设置docker开机自启
systemctl enable docker
7.使用 docker version 或 docker -v 测试是否安装成功创建Swarm并添加节点
1、创建swarm集群
# manager节点执行以下命令
[root@manager ~]# docker swarm init --advertise-addr 192.168.58.151
Swarm initialized: current node (pzvvc7ko4xflq024mnoo1tjmf) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-0rta6xdpbwcya1l2jhq4xf32bygqv1dau9z6kctl0e93y5mwe2-6jprqypdft8rhp9jv9xjbzghl 192.168.58.151:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.2、查看集群的相关信息
# 查看集群中目前已存在的机器
[root@manager ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
pzvvc7ko4xflq024mnoo1tjmf * manager Ready Active Leader 20.10.93、 添加节点主机到Swarm集群
# 上面我们在创建Swarm集群的时候就已经给出了添加节点的方法
[root@worker1 ~]# docker swarm join --token SWMTKN-1-0rta6xdpbwcya1l2jhq4xf32bygqv1dau9z6kctl0e93y5mwe2-6jprqypdft8rhp9jv9xjbzghl 192.168.58.151:2377
This node joined a swarm as a worker.
[root@worker2 ~]# docker swarm join --token SWMTKN-1-0rta6xdpbwcya1l2jhq4xf32bygqv1dau9z6kctl0e93y5mwe2-6jprqypdft8rhp9jv9xjbzghl 192.168.58.151:2377
This node joined a swarm as a worker.# 再次在manager节点上查看集群相关信息
[root@manager ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
pzvvc7ko4xflq024mnoo1tjmf * manager Ready Active Leader 20.10.9
npevvhuiq57g3zgmgyzqyuhg9 worker1 Ready Active 20.10.9
b9zebfwf6dgzl348y4ox60l1s worker2 Ready Active 20.10.9退出集群
# 在worker节点上执行,可以用来退出集群
[root@worker2 ~]# docker swarm leave
Node left the swarm.
# 然后在manager节点上删除已经退出集群的worker2节点
[root@manager ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
pzvvc7ko4xflq024mnoo1tjmf * manager Ready Active Leader
npevvhuiq57g3zgmgyzqyuhg9 worker1 Ready Active
b9zebfwf6dgzl348y4ox60l1s worker2 Down Active
[root@manager ~]# docker node rm worker2
worker2
[root@manager ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
pzvvc7ko4xflq024mnoo1tjmf * manager Ready Active Leader
npevvhuiq57g3zgmgyzqyuhg9 worker1 Ready Active更改节点的availablity状态
swarm集群中node的availability状态可以为 active或者drain,其中:
active状态下,node可以接受来自manager节点的任务分派
drain状态下,node节点会结束task,且不再接受来自manager节点的任务分派(也就是下线节点)
# 将worker1节点下线。如果要删除worker1节点,命令是"docker node rm --force worker1"
[root@manager ~]# docker node update --availability drain worker1
worker1
[root@manager ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
pzvvc7ko4xflq024mnoo1tjmf * manager Ready Active Leader 20.10.9
npevvhuiq57g3zgmgyzqyuhg9 worker1 Ready Drain 20.10.9
b9zebfwf6dgzl348y4ox60l1s worker2 Ready Active 20.10.9
# 如上,当worker1的状态改为drain后,那么该节点就不会接受task任务分发,就算之前已经接受的任务也会转移到别的节点上。
# 再次修改为active状态(即将下线的节点再次上线)
[root@manager ~]# docker node update --availability active worker1
worker1
[root@manager ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
pzvvc7ko4xflq024mnoo1tjmf * manager Ready Active Leader 20.10.9
npevvhuiq57g3zgmgyzqyuhg9 worker1 Ready Active 20.10.9
b9zebfwf6dgzl348y4ox60l1s worker2 Ready Active 20.10.9在Swarm中部署服务
1、部署服务
[root@manager ~]# docker service create --name nginx01 -p 8080:80 --replicas 3 nginx
aq2ni2p5fwm4sipn3lss25n38
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged
# 查看正在运行服务的列表
[root@manager ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
aq2ni2p5fwm4 nginx01 replicated 3/3 nginx:latest *:8080->80/tcp2、查询Swarm中服务的信息
# 不加 --pretty 可以输出更详细的信息
[root@manager ~]# docker service inspect --pretty nginx01
ID: aq2ni2p5fwm4sipn3lss25n38
Name: nginx01
Service Mode: Replicated
Replicas: 3
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: nginx:latest@sha256:644a70516a26004c97d0d85c7fe1d0c3a67ea8ab7ddf4aff193d9f301670cf36
Init: false
Resources:
Endpoint Mode: vip
Ports:
PublishedPort = 8080
Protocol = tcp
TargetPort = 80
PublishMode = ingress# 查询哪个节点正在运行该服务
[root@manager ~]# docker service ps nginx01
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
tncgfw2q38vn nginx01.1 nginx:latest worker1 Running Running 12 minutes ago
3osieaaqvwqw nginx01.2 nginx:latest worker2 Running Running 11 minutes ago
t2gxqleb9drp nginx01.3 nginx:latest manager Running Running 11 minutes ago
# 如果上面命令执行后,上面的STATE字段中刚开始的服务状态为 Preparing ,需要等一会才能变为 Running 状态,其中最费时间的应该是下载镜像的过程3、访问端口
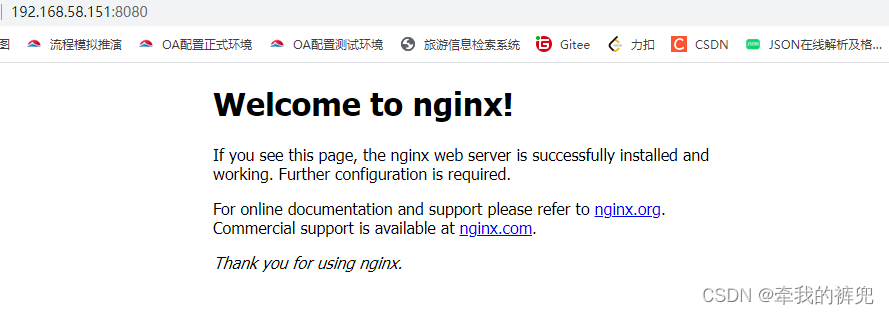
登陆worker节点,可以查看到nginx容器在运行中
[root@worker1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
140040f95064 nginx:latest "/docker-entrypoint.…" 4 minutes ago Up 4 minutes 80/tcp nginx01.1.tncgfw2q38vnibz3iini9roo3
[root@worker2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
40791e1baa8f nginx:latest "/docker-entrypoint.…" 4 minutes ago Up 4 minutes 80/tcp nginx01.2.3osieaaqvwqwt1skryyyf9xch4、 在Swarm中动态扩展服务(scale)
# Service还提供了复制(类似kubernetes里的副本)功能,可以通过 docker service scale 命令来设置服务中容器的副本数,这里我们将上面的nginx01容器动态扩展到5个
[root@manager ~]# docker service scale nginx01=5
nginx01 scaled to 5
overall progress: 5 out of 5 tasks
1/5: running [==================================================>]
2/5: running [==================================================>]
3/5: running [==================================================>]
4/5: running [==================================================>]
5/5: running [==================================================>]
verify: Service converged
[root@manager ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
aq2ni2p5fwm4 nginx01 replicated 5/5 nginx:latest *:8080->80/tcp
# 再来看一下nginx服务中的容器
[root@manager ~]# docker service ps nginx01
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
tncgfw2q38vn nginx01.1 nginx:latest worker1 Running Running 22 minutes ago
3osieaaqvwqw nginx01.2 nginx:latest worker2 Running Running 22 minutes ago
t2gxqleb9drp nginx01.3 nginx:latest manager Running Running 22 minutes ago
g4ubef25mqp5 nginx01.4 nginx:latest worker1 Running Running 3 minutes ago
jtvn3b24avb7 nginx01.5 nginx:latest manager Running Running 2 minutes ago 5、Swarm 动态缩容服务(scale)
# swarm还可以缩容,同样是使用scale命令
[root@manager ~]# docker service scale nginx01=2
nginx01 scaled to 2
overall progress: 2 out of 2 tasks
1/2: running [==================================================>]
2/2: running [==================================================>]
verify: Service converged
[root@manager ~]# docker service ps nginx01
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
tncgfw2q38vn nginx01.1 nginx:latest worker1 Running Running 26 minutes ago
3osieaaqvwqw nginx01.2 nginx:latest worker2 Running Running 26 minutes ago6、使用 docker service update 对参数进行修改
除了上面使用scale进行容器的扩容或缩容之外,还可以使用docker service update 命令对服务的启动参数进行更新和修改。
# 这里将容器由2个动态扩展到3个
[root@manager ~]# docker service update --replicas 3 nginx01
nginx01
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged
[root@manager ~]# docker service ps nginx01
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
tncgfw2q38vn nginx01.1 nginx:latest worker1 Running Running 31 minutes ago
3osieaaqvwqw nginx01.2 nginx:latest worker2 Running Running 30 minutes ago
wnezvvpsyjk8 nginx01.3 nginx:latest manager Running Running 23 seconds ago
# 对已经使用的镜像滚动升级
[root@manager ~]# docker service update --image nginx:latest nginx01
nginx01
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged 7、模拟宕机worker节点
在swarm cluster集群中启动的容器,在worker node节点上删除或停用后,该容器会自动转移到其他的worker node节点上。
# 如果一个节点宕机了(即该节点就会从swarm集群中被踢出),则Docker应该会将在该节点运行的容器,调度到其他节点,以满足指定数量的副本保持运行状态
[root@worker2 ~]# systemctl stop docker
[root@manager ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
pzvvc7ko4xflq024mnoo1tjmf * manager Ready Active Leader
npevvhuiq57g3zgmgyzqyuhg9 worker1 Ready Active
b9zebfwf6dgzl348y4ox60l1s worker2 Down Active
# 查询服务的状态列表,我们可以发现worker2节点故障后,它上面之前的1个task任务已经转移到manager节点上了
[root@manager ~]# docker service ps nginx01
ID NAME IMAGE NODE DESIRED STATE
0iog3ge6y20u nginx01.1 nginx:latest manager Running
jz8gdbu70wy1 \_ nginx01.1 nginx:latest worker2 Shutdown
qszwyli49co6 nginx01.2 nginx:latest manager Running
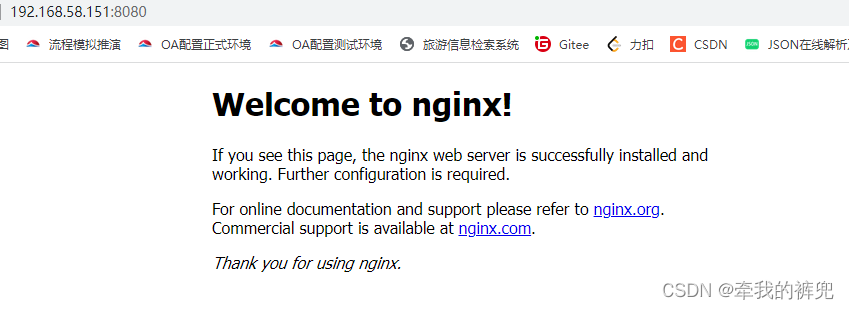
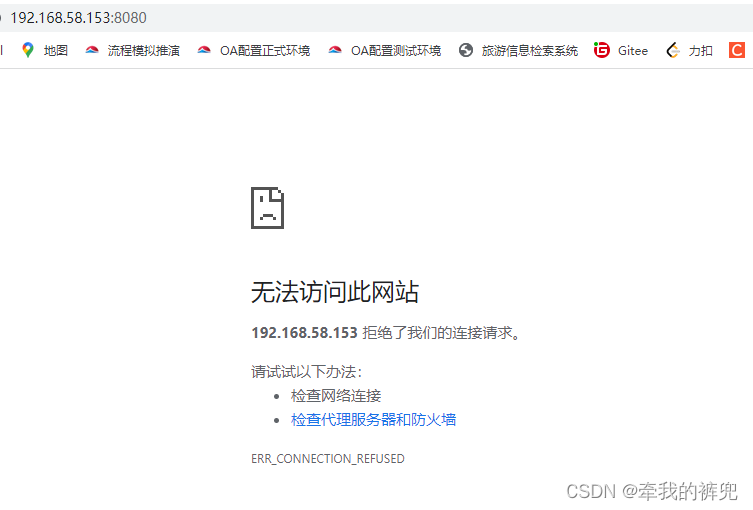
wjxlpsjjhuyi nginx01.3 nginx:latest worker1 Running当访问192.168.58.151和192.168.58.152节点的8080端口,swarm的负载均衡会把请求路由到一个任意节点的可用的容器上,而访问192.168.58.153节点的8080端口,由于worker2节点宕机了,所以无法访问。
8、删除服务
[root@manager ~]# docker service rm nginx01
nginx01
# 查看服务,发现已经被删除了
[root@manager ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)