kubectl get nodes缓慢问题排查
微信公众号:运维开发故事,作者:华仔问题描述最近在某个k8s集群其中一个节点(master1)上执行kubectl get nodes大概需要45s的时间才有数据返回,而在另外的master上执行同样的命令却是很快返回。通过kube-apiserver的日志来看,是无法连接上metrics-server,从而导致超时。进而发现这个master无法与其他节点的flannel.1的IP互相ping通。
微信公众号:运维开发故事,作者:华仔
问题描述
最近在某个k8s集群其中一个节点(master1)上执行kubectl get nodes大概需要45s的时间才有数据返回,而在另外的master上执行同样的命令却是很快返回。通过kube-apiserver的日志来看,是无法连接上metrics-server,从而导致超时。进而发现这个master无法与其他节点的flannel.1的IP互相ping通。于是就有了这一篇文章。
排查结果
因为我们的网络组件使用的canal,跨主机通信时,通过flannel(vxlan)。除master1以外,其他节点的arp中master1上的flannel.1对应的mac地址缺失,最后是通过重启canal组件解决。
排查过程
环境信息
| 项目 | 说明 |
|---|---|
| kubernetes | v1.14.8 |
| 部署方式 | apiserver、conroller、scheduler、proxy均是以静态pod方式部署 |
| cni | canal(flannel-vxlan),daemonset部署 |
| master1 | 192.168.1.140 |
| master2 | 192.168.1.141 |
| master3 | 192.168.1.142 |
| node1 | 192.168.1.143 |
| node2 | 192.168.1.144 |
| node3 | 192.168.1.145 |
注:由于是master1有问题,其他节点无问题,因此以下拿master1与master3进行说明
1.在master1上执行kubectl get nodes大概需要45s,如下:
[root@master1 ~]$ time kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready <none> 100d v1.14.8
master2 Ready <none> 100d v1.14.8
master3 Ready <none> 100d v1.14.8
node1 Ready <none> 100d v1.14.8
node2 Ready <none> 100d v1.14.8
real 0m45.0s
同时在master3执行kubectl get nodes,很快返回,如下:
[root@master3 ~]$ time kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready <none> 100d v1.14.8
master2 Ready <none> 100d v1.14.8
master3 Ready <none> 100d v1.14.8
node1 Ready <none> 100d v1.14.8
node2 Ready <none> 100d v1.14.8
real 0m0.452s
开始认为是master1资源的问题(也不知道怎么想的),检查了一下,都正常。
2.因为执行kubectl命令会经过kube-apiserver,于是查看master1的apiserver的日志,如下:
E1124 11:40:21.145 1 available_controller.go:353] v1beta1.custom.metrics.k8s.io failed with: Get https://10.68.225.236:443: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
E1124 11:40:22.237 1 available_controller.go:353] v1beta1.custom.metrics.k8s.io failed with: Get https://10.68.225.236:443: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
E1124 11:40:23.358 1 available_controller.go:353] v1beta1.custom.metrics.k8s.io failed with: Get https://10.68.225.236:443: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
E1124 11:40:34.469 1 available_controller.go:353] v1beta1.custom.metrics.k8s.io failed with: Get https://10.68.225.236:443: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
以上,很明显是无法连接到metrics。尝试在master1和master3上进行telnet 10.68.225.236 443,结果如下:
master1:
[root@master1 ~]$ telnet 10.68.225.236 443
Trying 10.68.225.236...
master3:
[root@master3 ~]$ telnet 10.68.225.236 443
Trying 10.68.225.236...
Connected to 10.68.225.236.
Escape character is '^]'.
查看metrics的pod所在节点,如下:
[root@master3 ~]$ kubectl get pod -A -o wide |grep "metric" |awk '{print $1,$2,$7,$8}'
kube-system monitoring-kube-state-metrics-metrics-v1-0-645bc4cb6f-ch5dz 10.68.4.133 node1
kube-system monitoring-metrics-server-server-v1-0-6ff56d4d6d-fk9gd 10.68.3.210 node2
kube-system monitoring-metrics-server-server-v1-0-6ff56d4d6d-n7zgz 10.68.5.192 node3
很显然metrics不在master1上,也不再master3上,而master1不能与之通信,而master3可以,说明master1跨主机通信时,有问题。
3.canal在pod跨主机通信时,参考flannel(vxlan)数据流向,如下图所示:
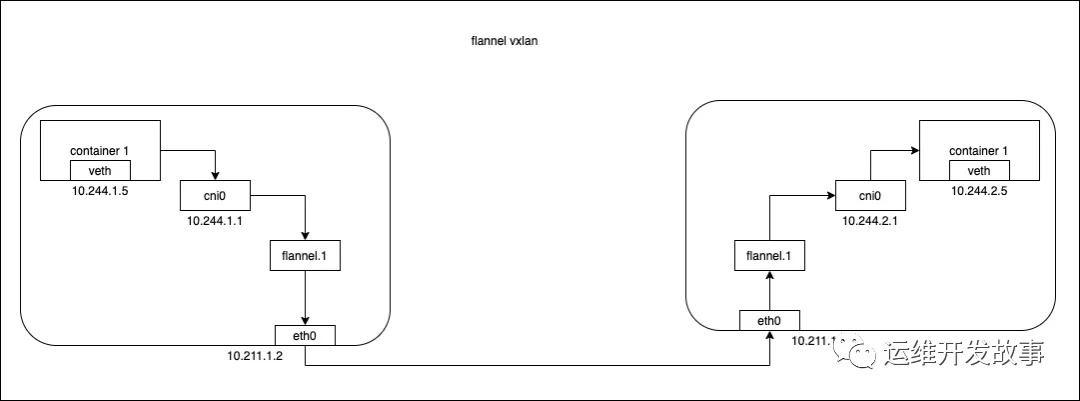
整个过程需要封包解包(这里就不说具体的啦),需要通过主机网络。
尝试去看看master1与master3的arp与fdb,如下:
master1:
[root@master1 ~]$ ip neigh |grep flannel.1
10.68.1.0 dev flannel.1 lladdr 16:23:8e:ab:c6:5c PERMANENT
10.68.4.0 dev flannel.1 lladdr 82:67:5t:5f:43:3b PERMANENT
10.68.2.0 dev flannel.1 lladdr a2:23:78:a5:7d:de PERMANENT
10.68.3.0 dev flannel.1 lladdr 32:a3:2r:8e:fb:2r PERMANENT
[root@master1 ~]$ bridge fdb | grep flannel.1
32:a3:2r:8e:fb:2r dev flannel.1 dst 192.168.1.143 self permanent
a2:23:78:a5:7d:de dev flannel.1 dst 192.168.1.141 self permanent
16:23:8e:ab:c6:5c dev flannel.1 dst 192.168.1.142 self permanent
82:67:5t:5f:43:3b dev flannel.1 dst 192.168.1.144 self permanent
master3:
[root@master3 ~]$ ip neigh |grep flannel.1
10.68.0.0 dev flannel.1 INCOMPLETE
10.68.4.0 dev flannel.1 lladdr 82:67:5t:5f:43:3b PERMANENT
10.68.2.0 dev flannel.1 lladdr a2:23:78:a5:7d:de PERMANENT
10.68.3.0 dev flannel.1 lladdr 32:a3:2r:8e:fb:2r PERMANENT
[root@master3 ~]$ bridge fdb | grep flannel.1
32:a3:2r:8e:fb:2r dev flannel.1 dst 192.168.1.143 self permanent
a2:23:78:a5:7d:de dev flannel.1 dst 192.168.1.141 self permanent
82:67:5t:5f:43:3b dev flannel.1 dst 192.168.1.144 self permanent
36:9u:9c:53:4a:10 dev flannel.1 dst 192.168.1.140 self permanent
由master3可知,master1的flannel.1的mac地址缺失,因此认为,master1上的pod与其他节点上的pod通信时,数据包无法返回。也就是说master1与其他节点的flannel.1的IP是不通的。
4.以上只是猜想,但还是要抓包确认一下。
在master1上ping master3的flannel.1的IP,同时,在master1、master3上对eth0、flannel.1进行抓包,结果如下:
master1:
ping 10.68.1.0
master1抓包显示:
[root@master1 ~]$ tcpdump -lnni flannel.1 |grep 10.68.1.0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on flannel.1, link-type EN10MB (Ethernet), capture size 262144 bytes
13:24:07.618633 IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 28296, seq 1, length 64
13:24:08.618726 IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 28296, seq 2, length 64
13:24:09.618719 IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 28296, seq 3, length 64
13:24:10.618710 IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 28296, seq 4, length 64
13:24:11.618723 IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 28296, seq 5, length 64
[root@master1 ~]$ tcpdump -lnni eth0 |grep 10.68.1.0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 25177, seq 1, length 64
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 25177, seq 2, length 64
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 25177, seq 3, length 64
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 25177, seq 4, length 64
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 25177, seq 5, length 64
master3抓包显示:
[root@master3 ~]$ tcpdump -lnni eth0 |grep 10.68.0.0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 30689, seq 1, length 64
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 30689, seq 2, length 64
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 30689, seq 3, length 64
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 30689, seq 4, length 64
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 30689, seq 5, length 64
[root@master3 ~]$ tcpdump -lnni flannel.1 |grep 10.68.0.0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 30689, seq 1, length 64
ARP, Request who-has 10.68.0.0 tell 10.68.1.0, length 28
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 30689, seq 2, length 64
ARP, Request who-has 10.68.0.0 tell 10.68.1.0, length 28
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 30689, seq 3, length 64
ARP, Request who-has 10.68.0.0 tell 10.68.1.0, length 28
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 30689, seq 4, length 64
ARP, Request who-has 10.68.0.0 tell 10.68.1.0, length 28
IP 10.68.0.0 > 10.68.1.0: ICMP echo request, id 30689, seq 5, length 64
由以上可知,在master1,ping master3的flannel.1的IP时,数据包已经到了master3的flannel.1,但是因为mac信息无法获取,所以数据包无法返回。
5.由以上可知,除master1以外的其他节点的arp中缺少了master1的flannel.1的mac地址,导致数据包无法返回。而跨主机通信时,通过flannel,而负责维护这些信息的是flanneld。所以只需要重启一下canal即可重新刷新相关信息。
6.重启除master1以外节点的canal
kubectl delete po -n kube-system canal-xxx
7.查看master3的arp与fdb
[root@master3 ~]$ ip neigh |grep flannel.1
10.68.0.0 dev flannel.1 lladdr 36:9u:9c:53:4a:10 PERMANENT
10.68.4.0 dev flannel.1 lladdr 82:67:5t:5f:43:3b PERMANENT
10.68.2.0 dev flannel.1 lladdr a2:23:78:a5:7d:de PERMANENT
10.68.3.0 dev flannel.1 lladdr 32:a3:2r:8e:fb:2r PERMANENT
[root@master3 ~]$ bridge fdb | grep flannel.1
32:a3:2r:8e:fb:2r dev flannel.1 dst 192.168.1.143 self permanent
a2:23:78:a5:7d:de dev flannel.1 dst 192.168.1.141 self permanent
82:67:5t:5f:43:3b dev flannel.1 dst 192.168.1.144 self permanent
36:9u:9c:53:4a:10 dev flannel.1 dst 192.168.1.140 self permanent
8.在master1上执行kubectl get nodes
[root@master1 ~]$ time kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready <none> 100d v1.14.8
master2 Ready <none> 100d v1.14.8
master3 Ready <none> 100d v1.14.8
node1 Ready <none> 100d v1.14.8
node2 Ready <none> 100d v1.14.8
real 0m0.538s
user 0m0.153s
sys 0m0.104s
公众号:运维开发故事
github:https://github.com/orgs/sunsharing-note/dashboard
爱生活,爱运维
如果你觉得文章还不错,就请点击右上角选择发送给朋友或者转发到朋友圈。您的支持和鼓励是我最大的动力。喜欢就请关注我吧~

扫码二维码
关注我,不定期维护优质内容
温馨提示
如果你喜欢本文,请分享到朋友圈,想要获得更多信息,请关注我。
........................

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)