云计算的概念及关键技术
云计算的关键技术
·
1、云计算的概念
1.1概念
也可以是其他服务,云计算的核心理念就是按需服务,就像人使用水、电、天然气等资源一样。
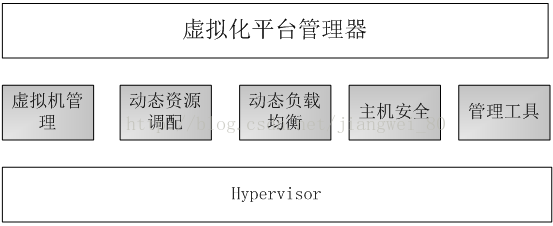
1.2关键技术
云计算的关键技术有:
虚拟化、
分布式文件系统、
分布式数据库、
资源管理技术、能耗管理技术。
机对物理资源的共享;
分布式文件系统:指在文件系统基础上发展而来的云存储分布式系统,可用于大规模的集群,主要特点:
1、高可靠性:云存储系统支持多个节点间保存多个数据副本的功能,以提供数据的可靠性;‘’
2、高访问性:根据数据的重要性和访问频率将数据分级多副本存储、热点数据并行读写,提高访问;
3、在线迁移、复制:存储节点支持在线迁移,复制、扩容不影响上层应用;
4、自动负载均衡:可以根据当前系统的负荷,将原有节点上的数据迁移到新增的节点上,特有的分片存储,以快为最小单位来存储,存储和查询时所有的存储节点并行计算;
5、元数据和数据分离:采用元数据和数据分离的存储方式设计分布式文件系统。
分布式数据库:能实现动态负载均衡、故障节点自动接管、具有高可靠性,高可用性、高可扩展性;
二、hadoop生态
在云计算这一块,hadoop算做的比较不错,hadoop平台的基本框图和生态系统如下所示:
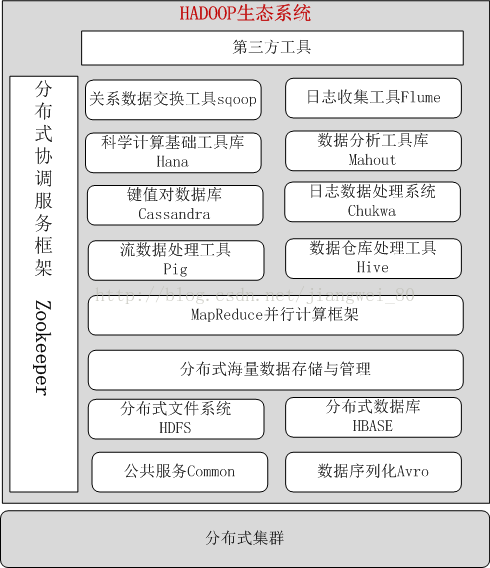
说明:
1、MapReduce:是一个并行化计算框架,提供了map和reduce两阶段的并行处理模型和过程,mapreduce以键值对的数据输入方式来处理数据,并能自动完成数据的划分和调度管理;
2、分布式文件系统(HDFS):基于物理上分布在各个数据存储节点的本地Linux系统的文件系统,为上次提供一个逻辑上成为整体的大规模数据存储系统;
3、分布式数据库管理系统(HBASE):克服了难以管理结构化/半结构化海量数据的缺点,提供了一个大规模分布式的,建立在HDFS之上的分布式数据库管理系统,Hbase提供了基于行,列和时间戳的三维数据管理模型;
4、公共服务模块(Common):为hadoop提供支撑服务和常用的工具类库以及api编程接口,服务包括:抽象文件系统fileSystem、远程过程调用(RPC),系统配置工具以及序列化机制;
6、分布式协调服务(Zookeeper):主要用户提供分布式应用经常需要的系统可靠性维护,数据状态同步、统一命名服务,分布式应用配置等管理功能;
7、分布式数据仓库处理工具(Hive):用于管理存在HDFS和hbase中的结构化/半结构化的数据。
8、数据流处理工具(Pig):用来处理大规模数据集平台,程序员可以使用它将复杂的数据分析任务实现为pig操作上的数据流脚本,这些脚本最终执行时将被系统自动转为mapreduce任务链,在hadoop上执行;
9、键值对数据库(Cassandro):是一个键值对数据库;
10、关系数据交换工具(Sqoop):可以将一个关系型数据库中的数据批量导入hadoop的HDFS,HBASE、Hive中,也可以反过来将数据导入关系型数据中。
11、日志数据收集工具(Flume):它将数据从生产、传输、处理、输出的过程抽象为数据流,并允许在数据源中定义数据发送方,从而支持基于各种不同传输协议的数据,同时也支持对数据的过滤,格转等能力。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)