微服务系统异常检测和根因定位 方法综述
CSUR22 - Anomaly Detection and Failure Root Cause Analysis in (Micro) Service-Based Cloud Applications: A Survey基于(微)服务的云应用中的异常检测与故障根源分析:综述总结到目前(2022),学术界故障检测和根因定位方法的综述当前的异常检测技术,都需要一个baseline去构建预知识。当线
CSUR22 - Anomaly Detection and Failure Root Cause Analysis in (Micro) Service-Based Cloud Applications: A Survey
基于(微)服务的云应用中的异常检测与故障根源分析:综述
www.fireknight.tech 个人博客,欢迎访问,CSDN不定期更新
总结
- 到目前(2022),学术界故障检测和根因定位方法的综述
- 当前的异常检测技术,都需要一个baseline去构建预知识。当线上执行差距过大(并发压力、环境、基础测试集构建错误等),会造成检测不准确
- 根因定位技术:各有千秋。基于拓扑的、概率/格兰杰假设的貌似会找出更多相关或者更接近根本的问题,相比基于trace比较的
摘要
- 检测故障和识别可能的根本原因,对于迅速恢复和修复应用程序至关重要
- 对现代多业务应用中当前可用的异常检测和根本原因分析技术进行结构化概述和定性分析
- 本论文结构为
- 异常检测技术
- 基于log的异常检测
- 基于分布式trace的异常检测
- 基于监控数据的异常检测
- 根因分析技术
- 基于log的
- 基于trace的
- 基于监控数据的
- 异常检测技术
Intro
- 向微服务松耦合变化
- 但是难以区分单独故障还是级联故障(多个服务jiaohu),难以检测和理解故障
- 目前异常检测(发现)和根因定位互相剥离,观察是否有相辅相成的工具【但目前我看到的大多异常检测和根因定位一起做】
术语
- 异常:服务响应时间变慢、吞吐降低or记录错误事件
- 根因分析与调试技术的区别:根本原因分析技术只是分析应用程序运行时收集的信息(例如,日志或监控数据),而不是在不同的条件下重新运行它【无关紧要的区别】
- 监控内容:KPIs(关键性能指标), log, trace
异常检测
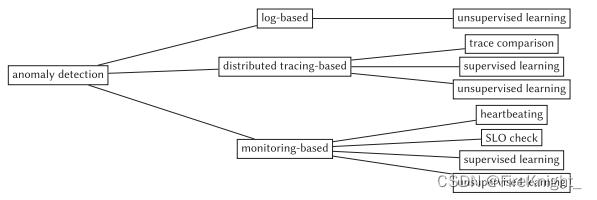
基于log的异常检测
- 无监督学习baseline,在线分析log是否与baseline是否相同
- OASIS [58]
- 先运行一个无错误的应用,提取log,挖掘一个控制流图,对正常条件下的基线应用行为进行建模。内含:应该由哪个服务记录哪些事件,记录的顺序是什么
- 然后,通过将新生成的日志映射到相应的模板,并检查到达的日志模板是否符合控制流图,实现在线异常检测。如果在相应的时间延迟中没有记录应该遵循模板的模板,或者遵循给定模板的模板的实际速率明显偏离预期的分支概率,那么OASIS认为应用程序受到了功能异常的影响。
- LogSed [34]:
- 时间加权流程图
- 总结:
- 共同假设:类似的事件会有类似的log。
- 但实际上服务是动态的,可能导致检测假阳性/假阴性
基于分布式追踪数据的异常检测
- trace获取 + (无监督/监督机器学习 | trace比较技术)
- 常见的假设是,应用程序在训练运行中产生的轨迹与运行时产生的轨迹是一致的,因此提供了一个基线,用来比较新产生的轨迹。
- 无监督机器学习
- 在生产前训练无监督网络,侦测生产过程中的问题
- TraceAnomaly [45]: 如果有新数据,则检查白名单,再给出阈值表示是否异常
- Nedelkoski [61]: LSTM
- 监督学习
- 标记+训练+判断
- MEPFL: 复旦WisdomCode团队工作 ((20220330164333-6snty44 ‘WisdomCode-MEPFL-基于日志学习的错误预测与故障定位’))
- trace对比技术
- trace相似度比较。收集多服务应用程序中可能出现的轨迹,然后检查新收集的轨迹是否与已收集的轨迹相似。
- 缺点:应用程序继续与以前的运行保持一致的情况下再次进行的,以前收集的跟踪提供了一个基线,用于比较新收集的跟踪。因此,当应用程序的运行时条件与收集基线轨迹时不同时,制定的异常检测的准确性可能会降低。
- Meng et al. [54] and Wang et al. [88]:预生成trace调用树 -> 新trace计算编辑距离,如歌超过阈值,则异常; 预生成响应时间矩阵 -> 主成分分析。 缺点:计算复杂度
- Chen et al. [17]: 使用fast matrix sketching algorithm做异常检测,优点:快
基于监控信息的异常检测
- 需要在无错误模式训练,然后在生产环境中定位问题。当应用程序运行时条件有所不同,检测的准确性可能减少,例如:由于高负荷由最终用户请求的山峰,或者由于新服务部署到取代过时的
- 监控数据
- SLI,全名Service Level Indicator,是服务等级指标的简称,它是衡定系统稳定性的指标。一个常见的SLI是请求得到正常响应的百分比。
- SLO,全名Sevice Level Objective,是服务等级目标的简称,也是稳定性目标,是围绕SLI构建的目标, 比如,月度、季度、年度等。
- 无监督学习
- 学习他们行为的基线模型。然后使用基线模型在线检测服务上新监控的kpi是否偏离基线模型
- MicroRCA[92]:并不算无监督,相当于图建模 ((20220510163942-ddm9aru ‘NOMS20-MicroRCA: Root Cause Localization ofPerformance Issues in…’))
- CloudRanger[87]:
- 应用程序的前端服务上实施持续学习,以根据监控的响应时间、负载和吞吐量,了解当前条件下的预期响应时间。
- 基于历史初始模型的脱机训练
- 当应用程序运行时,CloudRanger对监控的kpi应用多项式回归来更新基线模型,以反映应用程序在动态变化的运行时条件下的行为。
- 然后,根据给定的容错阈值,通过检查应用程序前端的响应时间是否明显偏离预期时间来实施在线异常检测。
- 监督学习
- 正常运行、注入特定的故障,生成训练集
- SLO检测
- ϵ-diagnosis [76]: 注重尾延迟
- Heartbeating
根因定位
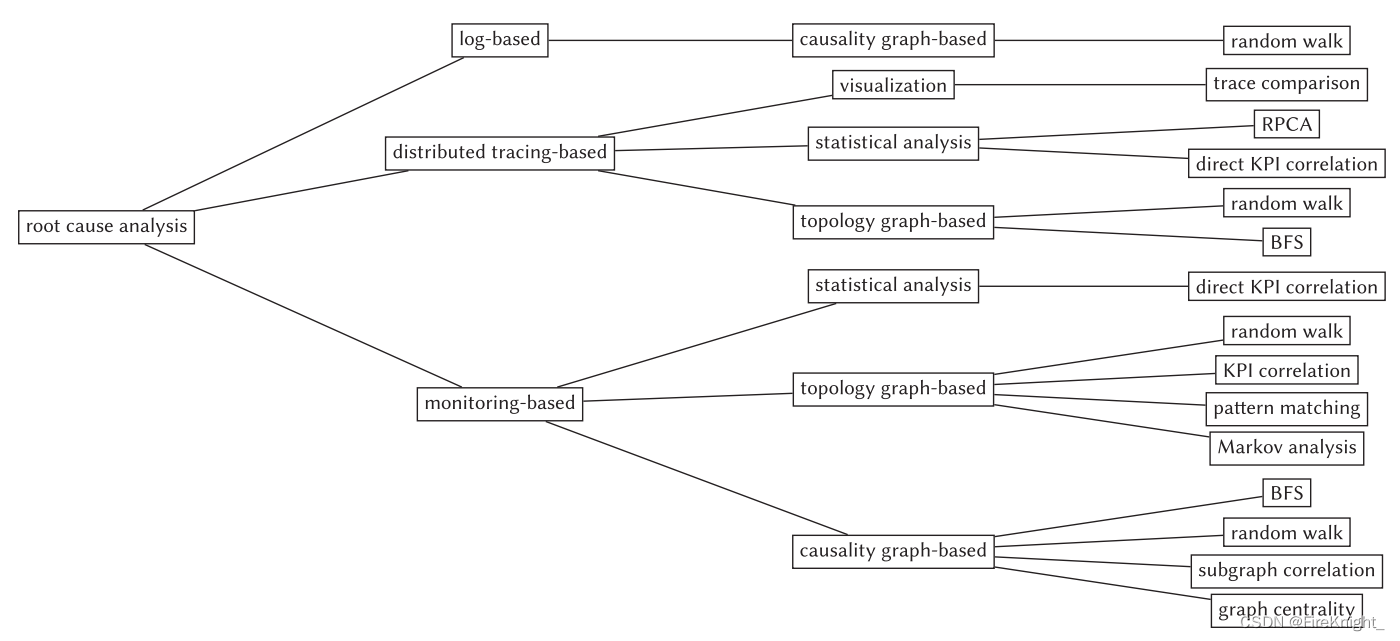
基于log的根因定位
- 建模,then确认异常
- Aggarwal et al. [1]:
- 因果关系图的顶点对应用程序服务进行建模,而因果关系图的有向弧则对源服务中的异常可能导致目标服务中的异常进行建模;
- 时间序列建模,计算格兰杰因果关系,确定错误记录之间的因果性
- 随机游走确定根因
基于trace的根因定位
-
方法:①可视化 ②统计分析 ③拓扑分析
-
可视化
- Zhou et al. [98]: ((20211126002021-vogdt0p ‘ITSE21-Fault Analysis and Debugging of MicroserviceSystems: Indu…’))
-
统计分析
- CloudDiag [56]: 变异系数, 阈值判断。基于主成分分析处理
- TraceAnomaly [45]: 神经网络,根据执行时间,把trace分为正常异常。每个响应时间与平均响应时间有显著偏差的服务交互都被认为是异常的
-
基于图
- MonitorRank [38]: 基于图的随机游走
- MicroHECL [44]: BFS, 找到异常, 用某种方法遍历所有节点,看节点传播能否到达异常
基于监控数据的根因定位
-
大多数基于监视的根本原因分析技术都依赖相关性作为驱动因素,以识别所观察到的异常的可能根本原因。其思想是,在异常服务上监控的kpi与在其他服务上并行监控的kpi之间的相关性越高,后者导致在前者上观察到的异常的可能性就越大
-
然而,考虑到相关性并不能确保因果关系,服务中观察到的异常的实际根本原因可能不在其监控kpi与异常服务高度相关的服务中,而在其他服务中。因此,伪相关性会影响利用KPI相关性进行统计分析或驱动拓扑/因果关系图中查找根本原因的技术。这增加了假阴性的风险,通常通过返回多个可能值来解决次问题
-
统计分析
- Wang et al. [86]: 通过识别其监控kpi与检测到的异常同时异常的应用程序服务,可以确定服务上检测到的异常的根本原因
- PAL [63]: CUSUM(累积和)图度量监视的KPI值的变化幅度,包括监视值的原始序列和自举序列,而自举序列是对所监视的KPI值进行随机排序的排列。如果原始序列的变化幅度高于大多数bootstrap,则认为原始序列是异常的,并根据其CUSUM图确定异常开始的时间。减少误报:为了减少误报,PAL和FChain检查异常是否影响了所有应用程序服务,在这种情况下,异常被归类为外部原因(如工作负载峰值)。相反,如果只有应用程序服务的子集异常,则认为它们是前端异常的可能根源,并按照异常开始时间的顺序返回它们。错误定位:最早的异常确实被认为是最有可能的根本原因,因为它们可能已经从相应的服务传播到其他服务,直到导致观测到的前端异常。
-
基于图的分析
- randomwalk:MicroRCA
- 其他方法,格兰杰因果测试等
-
因果关系图分析
- PC-algorithm
- BFS
- Random Walk
-
原理总结
-
因果图中的顶点要么为应用程序[18,19,24,42,43,48,50,87]建模,要么为这些服务上监视的KPI[51, 55, 68]建模,而每个弧线表示目标服务/KPI的性能取决于源服务/KPI的性能。
-
因果关系图总是通过对日志事件/监控kpi的时间序列应用pc -算法[82]来获得(但对于LOUD[51]),因为已知该算法允许确定时间序列中的因果关系,即:通过确定一个时间序列中的值是否可以用来预测另一个时间序列的值
-
搜索方法:从异常节点(服务/kpi)出发,BFS或者Random Walk
- randomwalk: 访问具有随机步长服务的概率与该服务的性能与观察到异常的服务之间的相关性成正比
-
讨论
- 成本
- 精度
- 假阳性解决方法
- 基线模型:不断训练新的模型
- trace解决方法:将新观察到的信息和之前的所有信息进行比较
- 假阳性解决方法
- 可解释性和对策

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)