昇思MindSpore全场景AI框架 1.6版本,更高的开发效率,更好地服务开发者
本文带大家快速浏览昇思MindSpore全场景AI框架1.6版本的关键特性。
本文分享自华为云社区《昇思MindSpore全场景AI框架 1.6版本,更高的开发效率,更好地服务开发者》,作者: 技术火炬手。
全新的昇思MindSpore全场景AI框架1.6版本已发布,此版本中昇思MindSpore全场景AI框架易用性不断改进,提升了开发效率,控制流性能提升并支持副作用训练,与此同时,昇思MindSpore全场景AI框架发布高效易用的图学习框架昇思MindSpore Graph Learning,高性能可扩展的强化学习计算框架昇思MindSpore Reinforcement,提供支持第三方框架模型迁移工具,让用户即时体验的开发套件昇思MindSpore Dev ToolKit,同时升级自定义算子能力支持高效添加算子,丰富MindQuantum量子模块支持可快速上手,持续提升框架的训练与推理性能,下面就带大家快速浏览昇思MindSpore全场景AI框架1.6版本的关键特性。
一、服务开发者,改进易用性提升开发效率
针对开发者诉求,昇思MindSpore全场景AI框架与开发者开展了系统、深入的交流,组织一系列用户调研和访谈,对开发者反馈较多的API问题进行整改优化,并打造系列教程,帮助开发者上手;同时,昇思MindSpore全场景AI框架积极吸纳开发者参与内容建设,累计吸引142名外部开发者贡献610+技术干货案例,覆盖安装、开发调优等关键场景,为开发者提供经验指导。
在调试、调优等功能特性上,昇思MindSpore全场景AI框架进行了系统的改进,帮助开发者提升开发效率:
- 在功能调试方面,支持静态图模式的问题代码堆栈打印、优化错误描述提升报错准确性,为用户提供更好的问题处理体验。
- 昇思MindSpore Insight提供集群性能数据一键收集、并行策略分析、图码联动可视化调优等功能,提升开发者性能和精度调优效率。
- 在ModelZoo模型方面,提供300+线上线下一致、覆盖CV/NLP/推荐等领域、支持跨平台部署的模型,并满足人工智能计算中心、金融、制造、终端等行业需求。基于新版本高效语法,重构Yolo v5等ModelZoo模型,为开发者提供昇思MindSpore全场景AI框架模型最佳实践。
二、控制流支持副作用训练,持续优化性能
在之前发布的昇思MindSpore全场景AI框架版本中,控制流训练场景下存在复制子图的问题,该问题会导致执行网络性能变差、副作用训练场景结果不对等问题。最新的昇思MindSpore全场景AI框架1.6.1版本,我们对控制流的IR表达设计进行了重构,消除了不必要的图复制,对控制流场景下各方面进行了较大的优化。
1.支持训练场景使用Assign等副作用算子。
2.优化控制流子图数量,反向网络可直接复用正向图算子结果,不需要重复计算正向图,提升了执行性能和编译性能。
例如:AirNet网络子图数量由原来的162个降低至46个,减少了大量冗余计算,执行性能由12.3s/epoch优化至5.8s/epoch。
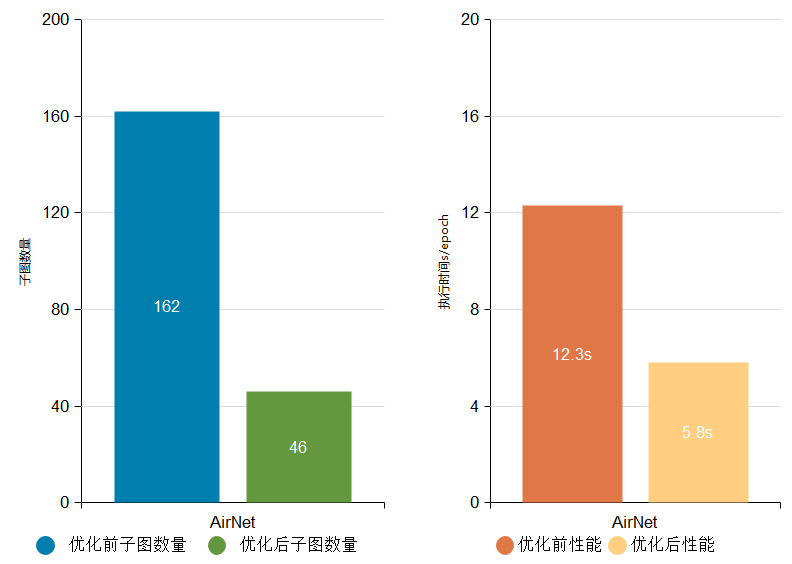
AirNet网络优化前后子图数量与执行性能对比
BFGS网络子图数量由原来的3236个降低至91个,执行性能由4.9s/epoch优化至0.6s/epoch。
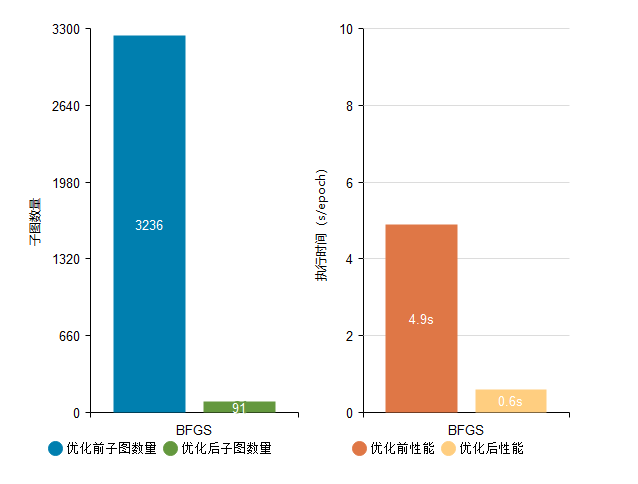
BFGS网络优化前后子图数量与执行性能对比
3.支持数据无依赖子图并行执行,同时优化了空子图执行流程,整体上提升控制流场景执行性能。
例如:Mappo(Agent3)网络优化前后子图数量无变化,但是由于我们优化了无数据依赖的子图的并行执行能力和空子图执行过程,网络最终执行性能由2.5s/epoch提升至1.8s/epoch。
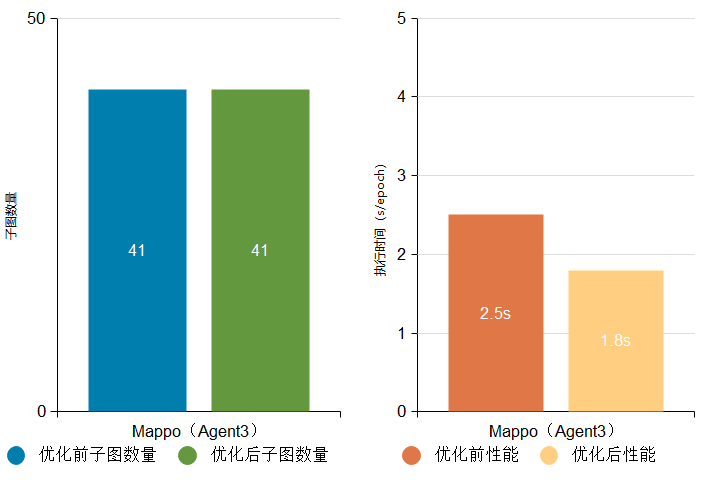
Mappo(Agent3)网络优化前后子图数量与执行性能对比
三、昇思MindSpore Graph Learning:公式即代码,训练加速3到4倍
图数据能自然表达真实世界对象之间的关系,表征能力和可解释性强,图学习也逐步广泛应用于电商推荐、金融风控、药物分子分析和控制优化等场景,图关系大都错综复杂,数据规模较大,通常有数十亿点,数百亿边,点边类型有几百种,图神经网络计算更加复杂耗时,因此迫切需要高效的图神经网络系统。同时,GNN算法的快速发展,需要易用的系统允许自由扩展。
昇思MindSpore Graph Learning是由James Cheng课题组(香港中文大学)、华为昇思MindSpore团队联合研发的图学习框架,具有高效性、易用性等特点。

3.1 易用性:公式即代码
通过创新性的提出以节点为中心的编程范式,相较于消息传递范式,更贴近GNN算法逻辑和Python语言风格,昇思MindSpore Graph Learning可以做到公式到代码的直接映射,如下图GAT网络代码所示。基于此,用户无需进行任何函数封装,即可快速直接地实现自定义的GNN算法/操作。

3.2 高效性:训练加速3到4倍
基于昇思MindSpore全场景AI框架的图算融合和自动算子编译技术(AKG)特性,创新提出基于索引的非规则内存访问算子融合,自动识别GNN模型运行任务特有执行pattern并进行融合和kernel level优化。相较于其他框架对常用算子进行定制优化的方案更加灵活,更具扩展性,能够覆盖现有框架中已有的算子和新组合算子的融合优化。以昇思MindSpore全场景AI框架作为后端,昇思MindSpore Graph Learning能使GNN网络训练获得3到4倍的性能加速。
3.3 丰富性:覆盖业界典型图学习网络
框架中已经自带实现十三种图网络学习模型,涵盖同构图、异构图、 随机游走等类型的应用网络。
详情请参考这里https://gitee.com/mindspore/graphlearning/tree/research/model_zoo
四、高性能可扩展的强化学习计算框架:昇思MindSpore Reinforcement
强化学习(RL)是近年来AI领域的研究热点之一,伴随昇思MindSpore全场景AI框架 1.6版本推出了独立的强化学习计算框架昇思MindSpore Reinforcement,通过框架中的Python 编程API以及算法与执行分离的设计使其具有易编程,可扩展等特点,期望带给用户一个全新的开发体验。
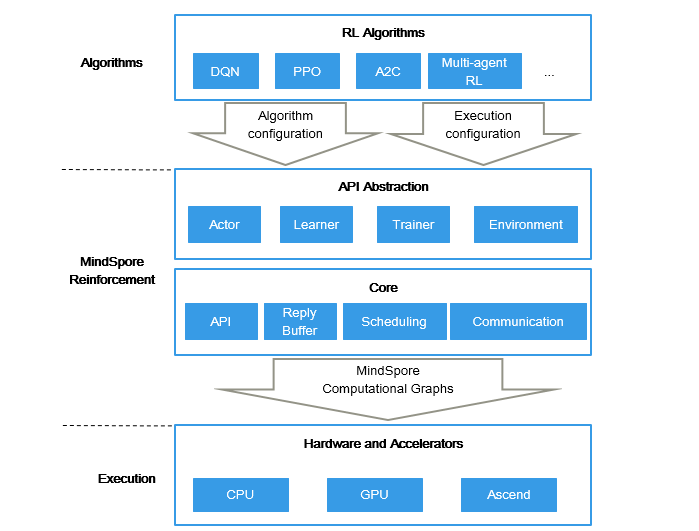
在昇思MindSpore Reinforcement 0.2版本中提供了一套面向强化学习领域的Python编程API,例如Actor用于环境交互获得奖励,Learner学习并更新策略,以及Trainer用于控制算法逻辑等抽象,使整个算法结构更加清晰、简洁,有助于高效的算法开发和模块复用;另外在仓库中内置了一些经典的强化学习算法,如DQN、PPO等(后续版本中将会持续更新),用户可直接运行其中的算法,或者基于Python API开发新的单智能体以及多智能体强化学习算法。
昇思MindSpore Reinforcement在架构设计上采用了算法表达和编译执行分离的设计思路,用户仅需要专注于强化学习算法逻辑的Python实现,依托于昇思MindSpore全场景AI框架强大的编译优化以及多硬件异构加速能力,可以实现强化学习算法的多硬件协同计算加速。
在计算设备上,昇思MindSpore Reinforcement支持包括Ascend、GPU、CPU在内的多硬件计算,当前0.2版本已支持单机训练,后续版本将提供更强大的多智能体分布式训练能力,以及更加丰富的特性支持,敬请大家持续关注。
查看文档:https://www.mindspore.cn/reinforcement
五、自定义算子能力全面升级,统一Custom接口帮助用户高效添加算子
随着AI模型的迭代,昇思MindSpore全场景AI框架内置的静态的算子库可能无法满足用户的需求,之前版本的昇思MindSpore全场景AI框架的自定义算子功能也存在着平台覆盖不到位,开发过程繁琐及第三方算子接入困难的问题。为了提供更好的自定义算子体验,昇思MindSpore全场景AI框架1.6版本全面升级了自定义算子的能力,提供支撑包括Ascend,GPU和CPU在内的多平台的统一算子开发接口Custom,帮助用户在昇思MindSpore全场景AI框架方便快捷地进行不同类型自定义算子的定义和使用,可以满足包括快速验证,实时编译和第三方算子接入等不同场景下的用户需求。
查看文档:https://www.mindspore.cn/docs/programming_guide/zh-CN/r1.6/custom_operator_custom.html
5.1 多场景、多平台的统一算子开发接口
昇思MindSpore全场景AI框架1.6版本提供统一的算子开发接口Custom,实现了不同方式自定义算子的接口和使用统一。其提供的模式包括基于JIT编译的算子编译器开发模式、针对极致性能的aot模式和针对快速验证的pyfunc模式,方便网络开发者根据需要灵活选用不同的自定义方式。
此外统一的算子开发接口整合了当前昇思MindSpore全场景AI框架支持的不同平台,包括Ascend,GPU和CPU,以及新增的AICPU平台,减少了用户针对不同平台算子开发的学习成本。
5.2 自定义算子一键接入,方便快捷
昇思MindSpore全场景AI框架1.6版本提供的自定义算子可以帮助用户在昇思MindSpore全场景AI框架的Python端快速的定义算子,把算子作为网络表达的一部分,无需对昇思MindSpore全场景AI框架进行侵入式修改和重新编译。此外提供了自动生成注册信息的能力,实现自定义算子一键接入网络,极大的简化了自定义算子的开发流程。用户在使用时完全不感知框架相关的设定,让用户更加关注计算本身。
5.3 新的自定义算子类型支持:AICPU
昇思MindSpore全场景AI框架1.6版本新增了AICPU类型算子的支持,该类算子对应的硬件架构为ARM架构,采用aot模式编译,可以快捷地部署到主流嵌入式平台上。AICPU算子相对于TBE算子,擅长逻辑类操作,采用C/C++开发,类似于CPU算子开发,对于一些难以向量化的算子,有较大的性能收益。
查看文档:https://www.mindspore.cn/docs/programming_guide/zh-CN/r1.6/custom_operator_custom.html#aicpu
六、模型迁移工具MindConverter:支持第三方框架模型的一键迁移
从第三方框架切换到昇思MindSpore全场景AI框架,如果不能复用原框架的存量主流模型,则需要重新编写模型训练脚本,并花费周级甚至月级的时间进行重训。目前大量开源模型基于PyTorch/TensorFlow实现,如果想基于昇思MindSpore全场景AI框架进行研究,则可能因为预训练数据无法获取或者训练资源有限,难以在昇思MindSpore全场景AI框架下复现模型。
在昇思MindSpore全场景AI框架1.6版本中提供的模型迁移工具MindConverter,可以帮助用户快速实现第三方框架主流模型的一键迁移。

工具采用了主流AI框架IR到昇思MindSpore IR的转换方案,转换后的模型可推理可重训,模型脚本可读性较好。模型迁移工具支持以下两种转换方式:
6.1 基于ONNX IR转换
ONNX是一种开放式模型定义格式,业界主流AI框架均已支持将模型导出为ONNX格式。借助ONNX通用性,模型迁移工具可实现多种AI框架到昇思MindSpore全场景AI框架的转换。已验证支持ResNet系列、RegNet系列,HRNet系列,DeepLabV3系列,YOLO系列等模型。
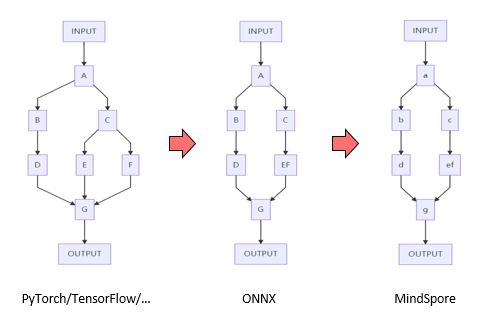
如上图所示,将第三方框架模型导出成ONNX格式,然后使用模型迁移工具,映射转换成昇思MindSpore全场景AI框架模型。
6.2 基于TorchScript IR转换
TorchScript是PyTorch模型的中间表达,借助 TorchScript IR 的泛化性,模型迁移工具可覆盖绝大部分的PyTorch模型。已验证支持HuggingFace Transformer预训练模型200+个。
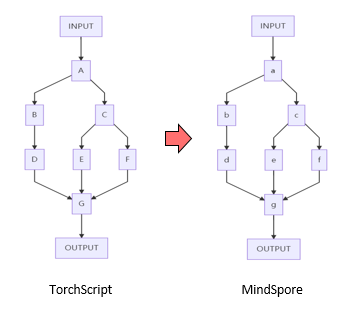
如上图所示,将PyTorch框架模型转换成TorchScript计算图,然后使用模型迁移工具,映射转换成昇思MindSpore全场景AI框架模型。
更多可支持转换的模型,有待用户发现与验证。使用模型迁移工具时如有问题,请参考官网的使用手册,也欢迎在开源社区中进行反馈。
使用手册:https://www.mindspore.cn/mindinsight/docs/zh-CN/r1.6/migrate_3rd_scripts_mindconverter.html
开源社区:https://gitee.com/mindspore/mindinsight/issues
七、使能用户即时体验的开发套件昇思MindSpore Dev ToolKit
昇思MindSpore全场景AI框架功能丰富且强大,如何一键上手,快速试用?由昇思MindSpore团队推出的昇思MindSpore Dev ToolKit开发套件包含运行管理,智能知识搜索与智能代码补全功能,致力于让所有用户丝滑地摆脱环境干扰,学习人工智能,让人工智能回归算法本身。
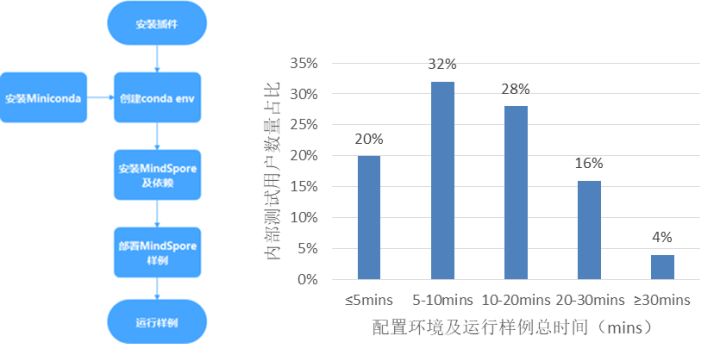
7.1 一键环境管理,5分钟完成环境搭建上手昇思MindSpore全场景AI框架实践
基于Conda提供科学的昇思MindSpore全场景AI框架环境管理方式,能快速将昇思MindSpore全场景AI框架及依赖安装在独立环境中并部署最佳实践。该能力兼容Ascend、GPU、CPU多平台,隐蔽不同环境适配的繁琐细节,让用户在打开IDE后一键运行AI算法。最快能在5分钟内体验用昇思MindSpore全场景AI框架学AI的乐趣,内测数据显示80%的AI零基础用户使用该功能可在20分钟内完成环境配置与算法运行。
7.2 沉浸式昇思MindSpore全场景AI框架生态知识智能搜索,用户零压力接入昇思MindSpore生态
基于语义搜索等能力,在Dev Toolkit内提供全面的昇思MindSpore全场景AI框架知识内容检索,对算子而言,PyTorch/TensorFlow框架用户只需在IDE内查询相应算子,即可快速准确找到昇思MindSpore全场景AI框架中的对应实现并获得详细文档支持,从而无压力切换到昇思MindSpore全场景AI框架生态中。
7.3 基于深度学习的智能代码补全,单模型开发键盘敲击次数可减少30%
Dev Toolkit基于昇思MindSpore ModelZoo等最佳实践数据集构造的智能代码补全模型实现的智能代码补全功能,让用户在编写昇思MindSpore全场景AI框架相关代码时获取实时提示,补全达80%的高准确性将加速用户编码,目前内测数据显示编码时键盘敲击次数可减少30%以上。
详情参考:https://gitee.com/mindspore/ide-plugin
八、昇思MindSpore Lite持续提升推理性能
8.1 通过异构并行技术,深度挖掘硬件算力提升推理性能
此版本中,昇思MindSpore Lite新增异构并行功能,该功能感知异构硬件能力,使能多个底层硬件并行执行推理,最大限度利用端侧有限的硬件资源,提升推理效率。
异构并行功能会在构图阶段,根据异构硬件的能力进行构图操作。构图操作分为切分算子与构造异构图两部分。切分算子会将原本不适合异构并行的模型重构成适合异构并行的,且并行分支的运算量能够严格匹配异构硬件的执行能力。构造异构图操作会根据模型现有的图结构进行并行子图搜索,最终确定异构并行图。构图的整体解决方案不局限于模型原始结构,使得异构并行可以应用于泛化模型。
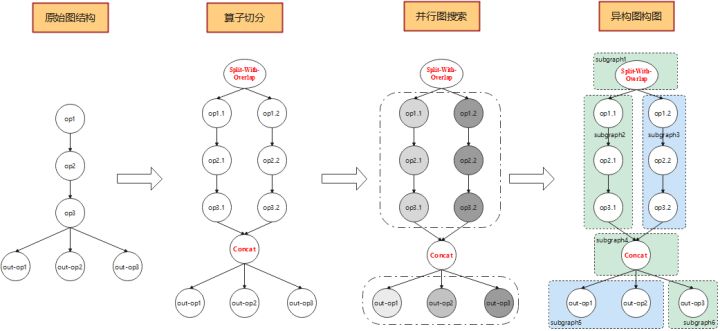
昇思MindSpore Lite在当前版本实现了GPU与CPU的异构并行,使用Mobilenet-V1网络实测验证,有5%左右的性能提升。
8.2 优化GPU推理性能,支持将OpenGL纹理数据作为输入和输出数据
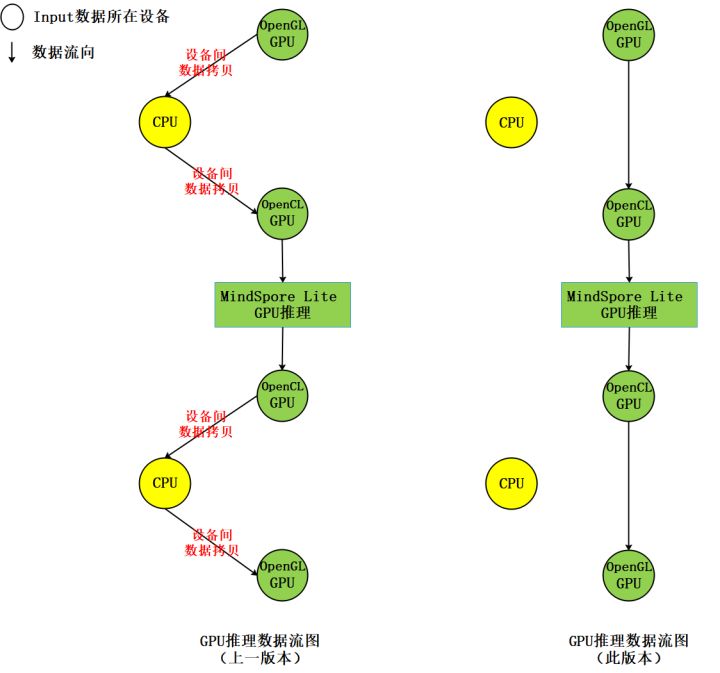
此版本中,昇思MindSpore Lite支持将OpenGL纹理数据作为推理模型的输入,推理输出结果也为OpenGL纹理,实现端到端推理过程中,减少CPU和GPU间的数据拷贝,从而达到提升推理性能降低功耗的目的;相比上一版本,能够减少四次设备间的内存拷贝,示意如下图:
查看文档:https://www.mindspore.cn/lite/docs/zh-CN/r1.6/use/runtime_cpp.html#opengl
九、MindQuantum:快速上手量子模拟与量子机器学习
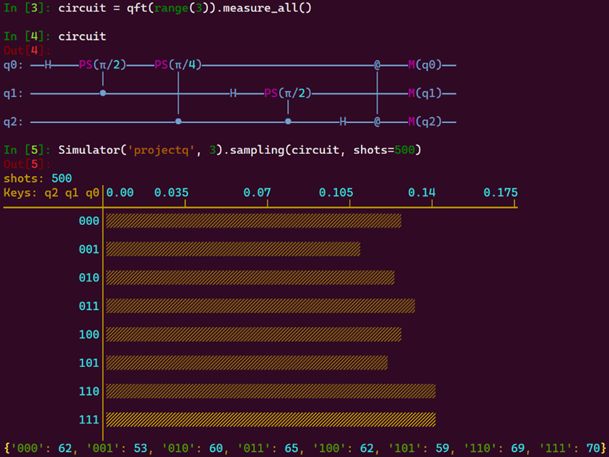
MindQuantum 最新0.5版本中提供独立的量子模拟模块Simulator,用户可快速对自定义量子线路进行模拟演化并对量子态进行采样,极大方便开发者在MindQuantum环境中设计和验证自己的量子算法。此外我们新增了量子线路和量子态采样的展示模块,开发者也能直观的对量子算法进行修改。
新增量子线路绘制功能演示如下:

新增模拟器模块及其线路采样功能演示如下:
此版本的第二大特性是新增了多种量子神经网络算子,开发者根据这些算子可以快速开发量子经典混合的机器学习模型,助力量子人工智能算法突破。

查看文档:https://www.mindspore.cn/mindquantum/docs/zh-CN/r1.6/index.html
十、昇思MindSpore Science蛋白质结构预测性能提升2-3倍
昇思MindSpore Science开源了基于AlphaFold2【1】算法的蛋白质结构预测推理工具,该预测推理工具由昇思MindSpore【2】团队、昌平实验室、北京大学生物医学前沿创新中心(BIOPIC)和化学与分子工程学院、深圳湾实验室高毅勤教授课题组联合推出,MindSpore + Ascend910 单卡端到端性能优于原版AlphaFold2达2-3倍。
传统的药物设计研发周期长、费用高,而了解蛋白质的空间结构后可大幅缩短研发周期。因此,准确、快速的蛋白质结构预测不仅可以快速获得或验证关键蛋白结构,而且在医疗健康和生物工程领域也能作为有力的工具。但传统蛋白质结构预测方法存在计算精度不足的缺陷,而AlphaFold2的蛋白质结构预测工具精度可与实验方法相媲美。
该工具可对氨基酸序列长度2000+的蛋白质结构解析,能覆盖约99%以上的蛋白序列【3】。其中模型部分与AlphaFold2相同,在多序列比对阶段,采用了MMseqs2进行序列检索【4】,相比于原版算法端到端运算速度有2-3倍的提升。
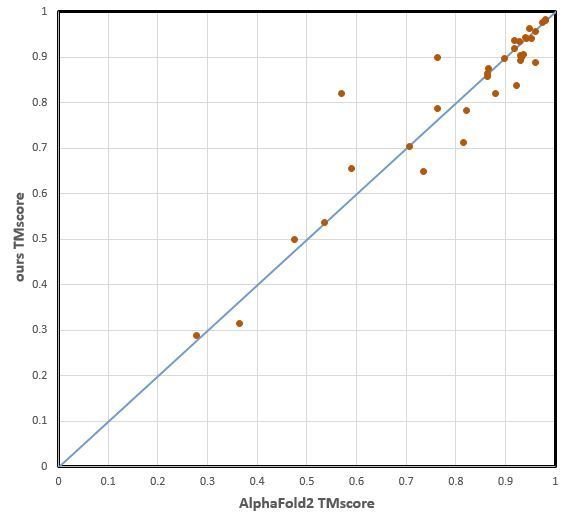
图1 昇思MindSpore全场景AI框架模型与AlphaFold2精度对比
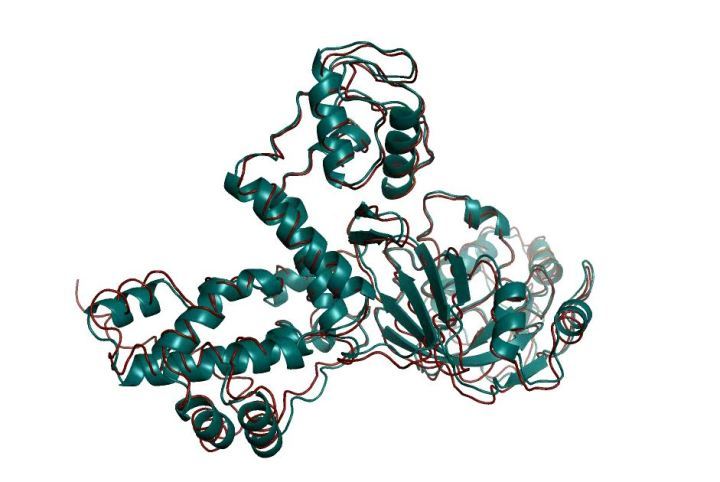
图2 通过昇思MindSpore全场景AI框架预测的T1079
针对蛋白质结构预测及折叠问题,联合团队未来还会发布创新的全栈(算法+软件+硬件)敬请期待。
详情请参考:https://gitee.com/mindspore/mindscience/tree/master/MindSPONGE/mindsponge/fold
参考文献
【1】Jumper J, Evans R, Pritzel A, et al. Applying and improving AlphaFold at CASP14[J]. Proteins: Structure, Function, and Bioinformatics, 2021
【2】Chen L. Deep Learning and Practice with MindSpore[M]. Springer Nature, 2021.
【3】https://ftp.uniprot.org/pub/databases/uniprot/previous_releases/release-2021_02/knowledgebase/UniProtKB_TrEMBL-relstat.html
【4】Mirdita M, Ovchinnikov S, Steinegger M. ColabFold-Making protein folding accessible to all[J]. BioRxiv, 2021.

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 0
0 0
0- 0



 已为社区贡献6164条内容
已为社区贡献6164条内容

所有评论(0)