文本分类:Keras+RNN vs传统机器学习
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比。
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比。
本文分享自华为云社区《基于Keras+RNN的文本分类vs基于传统机器学习的文本分类》,作者: eastmount 。
一.RNN文本分类
1.RNN
循环神经网络英文是Recurrent Neural Networks,简称RNN。RNN的本质概念是利用时序信息,在传统神经网络中,假设所有的输入(以及输出)都各自独立。但是,对于很多任务而言,这非常局限。举个例子,假如你想根据一句没说完的话,预测下一个单词,最好的办法就是联系上下文的信息。而RNN(循环神经网络)之所以是“循环”,是因为它们对序列的每个元素执行相同的任务,而每次的结果都独立于之前的计算。
假设有一组数据data0、data1、data2、data3,使用同一个神经网络预测它们,得到对应的结果。如果数据之间是有关系的,比如做菜下料的前后步骤,英文单词的顺序,如何让数据之间的关联也被神经网络学习呢?这就要用到——RNN。
比如存在ABCD数字,需要预测下一个数字E,会根据前面ABCD顺序进行预测,这就称为记忆。预测之前,需要回顾以前的记忆有哪些,再加上这一步新的记忆点,最终输出output,循环神经网络(RNN)就利用了这样的原理。
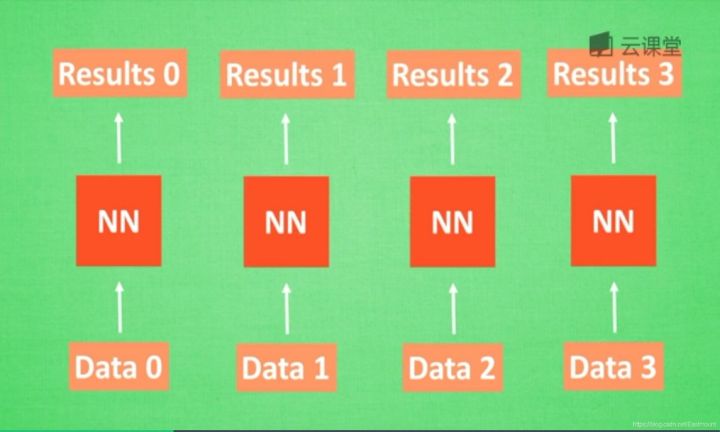
首先,让我们想想人类是怎么分析事物之间的关联或顺序的。人类通常记住之前发生的事情,从而帮助我们后续的行为判断,那么是否能让计算机也记住之前发生的事情呢?
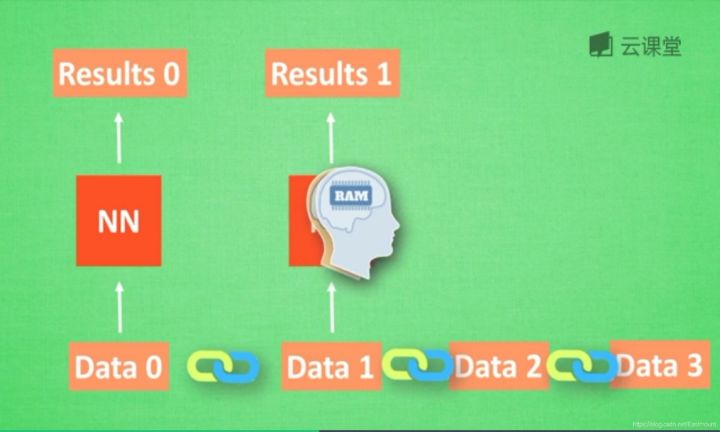
在分析data0时,我们把分析结果存入记忆Memory中,然后当分析data1时,神经网络(NN)会产生新的记忆,但此时新的记忆和老的记忆没有关联,如上图所示。在RNN中,我们会简单的把老记忆调用过来分析新记忆,如果继续分析更多的数据时,NN就会把之前的记忆全部累积起来。
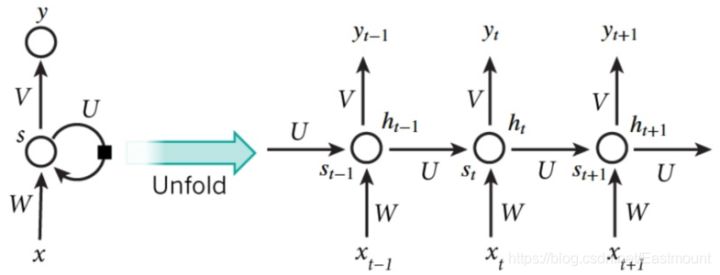
下面是一个典型的RNN结果模型,按照时间点t-1、t、t+1,每个时刻有不同的x,每次计算会考虑上一步的state和这一步的x(t),再输出y值。在该数学形式中,每次RNN运行完之后都会产生s(t),当RNN要分析x(t+1)时,此刻的y(t+1)是由s(t)和s(t+1)共同创造的,s(t)可看作上一步的记忆。多个神经网络NN的累积就转换成了循环神经网络,其简化图如下图的左边所示。例如,如果序列中的句子有5个单词,那么,横向展开网络后将有五层神经网络,一层对应一个单词。
总之,只要你的数据是有顺序的,就可以使用RNN,比如人类说话的顺序,电话号码的顺序,图像像素排列的顺序,ABC字母的顺序等。RNN常用于自然语言处理、机器翻译、语音识别、图像识别等领域。
2.文本分类
文本分类旨在对文本集按照一定的分类体系或标准进行自动分类标记,属于一种基于分类体系的自动分类。文本分类最早可以追溯到上世纪50年代,那时主要通过专家定义规则来进行文本分类;80年代出现了利用知识工程建立的专家系统;90年代开始借助于机器学习方法,通过人工特征工程和浅层分类模型来进行文本分类。现在多采用词向量以及深度神经网络来进行文本分类。
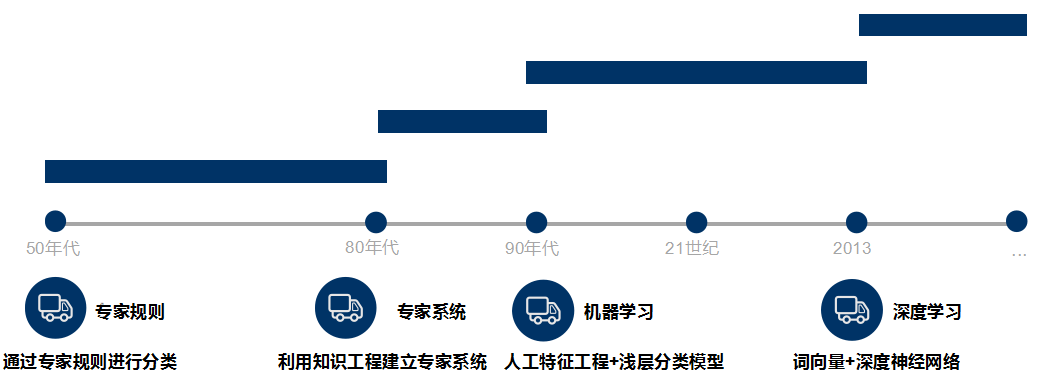
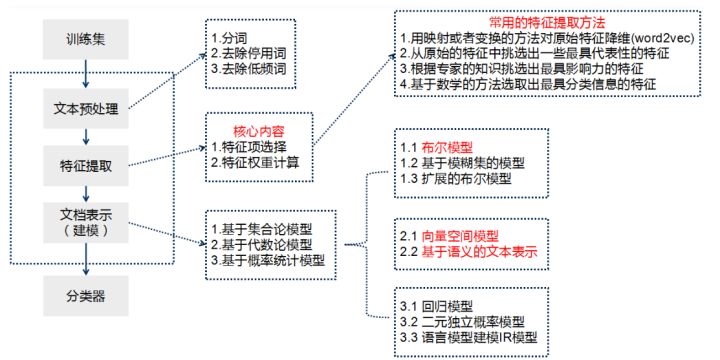
牛亚峰老师将传统的文本分类流程归纳如下图所示。在传统的文本分类中,基本上大部分机器学习方法都在文本分类领域有所应用。主要包括:
- Naive Bayes
- KNN
- SVM
- 集合类方法
- 最大熵
- 神经网络
利用Keras框架进行文本分类的基本流程如下:
- 步骤 1:文本的预处理,分词->去除停用词->统计选择top n的词做为特征词
- 步骤 2:为每个特征词生成ID
- 步骤 3:将文本转化成ID序列,并将左侧补齐
- 步骤 4:训练集shuffle
- 步骤 5:Embedding Layer 将词转化为词向量
- 步骤 6:添加模型,构建神经网络结构
- 步骤 7:训练模型
- 步骤 8:得到准确率、召回率、F1值
注意,如果使用TFIDF而非词向量进行文档表示,则直接分词去停后生成TFIDF矩阵后输入模型。本文将采用词向量、TFIDF两种方式进行实验。
深度学习文本分类方法包括:
推荐牛亚峰老师的文章:基于 word2vec 和 CNN 的文本分类 :综述 & 实践
二.基于传统机器学习贝叶斯算法的文本分类
1.MultinomialNB+TFIDF文本分类
数据集采用基基伟老师的自定义文本,共21行数据,包括2类(小米手机、小米粥)。其基本流程是:
- 获取数据集data和target
- 调用Jieba库实现中文分词
- 计算TF-IDF值,将词频矩阵转换为TF-IDF向量矩阵
- 调用机器学习算法进行训练和预测
- 实验评估及可视化分析
完整代码如下:
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 28 22:10:20 2020
@author: Eastmount CSDN
"""
from jieba import lcut
#--------------------------------载入数据及预处理-------------------------------
data = [
[0, '小米粥是以小米作为主要食材熬制而成的粥,口味清淡,清香味,具有简单易制,健胃消食的特点'],
[0, '煮粥时一定要先烧开水然后放入洗净后的小米'],
[0, '蛋白质及氨基酸、脂肪、维生素、矿物质'],
[0, '小米是传统健康食品,可单独焖饭和熬粥'],
[0, '苹果,是水果中的一种'],
[0, '粥的营养价值很高,富含矿物质和维生素,含钙量丰富,有助于代谢掉体内多余盐分'],
[0, '鸡蛋有很高的营养价值,是优质蛋白质、B族维生素的良好来源,还能提供脂肪、维生素和矿物质'],
[0, '这家超市的苹果都非常新鲜'],
[0, '在北方小米是主要食物之一,很多地区有晚餐吃小米粥的习俗'],
[0, '小米营养价值高,营养全面均衡 ,主要含有碳水化合物'],
[0, '蛋白质及氨基酸、脂肪、维生素、盐分'],
[1, '小米、三星、华为,作为安卓三大手机旗舰'],
[1, '别再管小米华为了!魅族手机再曝光:这次真的完美了'],
[1, '苹果手机或将重陷2016年困境,但这次它无法再大幅提价了'],
[1, '三星想要继续压制华为,仅凭A70还不够'],
[1, '三星手机屏占比将再创新高,超华为及苹果旗舰'],
[1, '华为P30、三星A70爆卖,斩获苏宁最佳手机营销奖'],
[1, '雷军,用一张图告诉你:小米和三星的差距在哪里'],
[1, '小米米聊APP官方Linux版上线,适配深度系统'],
[1, '三星刚刚更新了自家的可穿戴设备APP'],
[1, '华为、小米跨界并不可怕,可怕的打不破内心的“天花板”'],
]
#中文分析
X, Y = [' '.join(lcut(i[1])) for i in data], [i[0] for i in data]
print(X)
print(Y)
#['煮粥 时 一定 要 先烧 开水 然后 放入 洗净 后 的 小米', ...]
#--------------------------------------计算词频------------------------------------
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
#将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
#计算个词语出现的次数
X_data = vectorizer.fit_transform(X)
print(X_data)
#获取词袋中所有文本关键词
word = vectorizer.get_feature_names()
print('【查看单词】')
for w in word:
print(w, end = " ")
else:
print("\n")
#词频矩阵
print(X_data.toarray())
#将词频矩阵X统计成TF-IDF值
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X_data)
#查看数据结构 tfidf[i][j]表示i类文本中的tf-idf权重
weight = tfidf.toarray()
print(weight)
#--------------------------------------数据分析------------------------------------
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(weight, Y)
print(len(X_train), len(X_test))
print(len(y_train), len(y_test))
print(X_train)
#调用MultinomialNB分类器
clf = MultinomialNB().fit(X_train, y_train)
pre = clf.predict(X_test)
print("预测结果:", pre)
print("真实结果:", y_test)
print(classification_report(y_test, pre))
#--------------------------------------可视化分析------------------------------------
#降维绘制图形
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
pca = PCA(n_components=2)
newData = pca.fit_transform(weight)
print(newData)
L1 = [n[0] for n in newData]
L2 = [n[1] for n in newData]
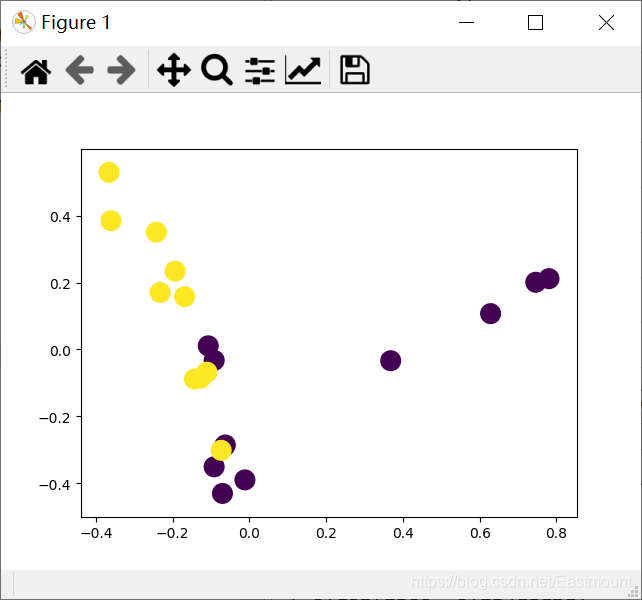
plt.scatter(L1, L2, c=Y, s=200)
plt.show()输出结果如下所示:
- 6个预测数据的accuracy ===> 0.67
['小米粥 是 以 小米 作为 主要 食材 熬 制而成 的 粥 , 口味 清淡 , 清香味 , 具有 简单 易制 , 健胃 消食 的 特点',
'煮粥 时 一定 要 先烧 开水 然后 放入 洗净 后 的 小米',
'蛋白质 及 氨基酸 、 脂肪 、 维生素 、 矿物质',
...
'三星 刚刚 更新 了 自家 的 可 穿戴 设备 APP',
'华为 、 小米 跨界 并 不 可怕 , 可怕 的 打 不破 内心 的 “ 天花板 ”']
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
【查看单词】
2016 app linux p30 一定 一张 一种 三星 健康 ... 雷军 食品 食材 食物 魅族 鸡蛋
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 1 ... 0 0 0]
[0 0 1 ... 0 0 0]
[0 0 0 ... 0 0 0]]
15 6
15 6
[[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0.32161043]
[0. 0. 0. ... 0. 0. 0. ]
...
[0. 0.31077094 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
[0.35882035 0. 0. ... 0. 0. 0. ]]
预测结果: [0 1 0 1 1 1]
真实结果: [0, 0, 0, 0, 1, 1]
precision recall f1-score support
0 1.00 0.50 0.67 4
1 0.50 1.00 0.67 2
accuracy 0.67 6
macro avg 0.75 0.75 0.67 6
weighted avg 0.83 0.67 0.67 6绘制图形如下图所示:
2.GaussianNB+Word2Vec文本分类
该方法与前面不同之处是采用Word2Vec进行词向量计算,将每行数据集分词,并计算每个特征词的词向量,接着转换为词向量矩阵,比如15行数据,每行数据40个特征词,每个特征词用20维度的词向量表示,即(15, 40, 20)。同时,由于词向量存在负数,所以需要使用GaussianNB算法替代MultinomialNB算法。
Word2Vec详见作者前文:[Python人工智能] 九.gensim词向量Word2Vec安装及《庆余年》中文短文本相似度计算
- sentences:传入的数据集序列(list of lists of tokens),默认值为None
- size:词向量维数,默认值为100
- window:同句中当前词和预测词的最大距离,默认值为5
- min_count:最低词频过滤,默认值为5
- workers:线程数,默认值为3
- sg:模型参数,其值为0表示CBOW,值为1表示skip-gram,默认值为0
- hs:模型参数,其值为0表示负例采样,值为1表示层次softmax,默认值为0
- negative:负例样本数,默认值为5
- ns_exponent:用于形成负例样本的指数,默认值为0.75
- cbow_mean:上下文词向量参数,其值为0表示上下文词向量求和值,值为1表示上下文词向量平均值,默认值为1
- alpha:初始学习率,默认值为0.025
- min_alpha:最小学习率,默认值为0.0001
完整代码如下:
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 28 22:10:20 2020
@author: Eastmount CSDN
"""
from jieba import lcut
from numpy import zeros
from gensim.models import Word2Vec
from sklearn.model_selection import train_test_split
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
max_features = 20 #词向量维度
maxlen = 40 #序列最大长度
#--------------------------------载入数据及预处理-------------------------------
data = [
[0, '小米粥是以小米作为主要食材熬制而成的粥,口味清淡,清香味,具有简单易制,健胃消食的特点'],
[0, '煮粥时一定要先烧开水然后放入洗净后的小米'],
[0, '蛋白质及氨基酸、脂肪、维生素、矿物质'],
[0, '小米是传统健康食品,可单独焖饭和熬粥'],
[0, '苹果,是水果中的一种'],
[0, '粥的营养价值很高,富含矿物质和维生素,含钙量丰富,有助于代谢掉体内多余盐分'],
[0, '鸡蛋有很高的营养价值,是优质蛋白质、B族维生素的良好来源,还能提供脂肪、维生素和矿物质'],
[0, '这家超市的苹果都非常新鲜'],
[0, '在北方小米是主要食物之一,很多地区有晚餐吃小米粥的习俗'],
[0, '小米营养价值高,营养全面均衡 ,主要含有碳水化合物'],
[0, '蛋白质及氨基酸、脂肪、维生素、盐分'],
[1, '小米、三星、华为,作为安卓三大手机旗舰'],
[1, '别再管小米华为了!魅族手机再曝光:这次真的完美了'],
[1, '苹果手机或将重陷2016年困境,但这次它无法再大幅提价了'],
[1, '三星想要继续压制华为,仅凭A70还不够'],
[1, '三星手机屏占比将再创新高,超华为及苹果旗舰'],
[1, '华为P30、三星A70爆卖,斩获苏宁最佳手机营销奖'],
[1, '雷军,用一张图告诉你:小米和三星的差距在哪里'],
[1, '小米米聊APP官方Linux版上线,适配深度系统'],
[1, '三星刚刚更新了自家的可穿戴设备APP'],
[1, '华为、小米跨界并不可怕,可怕的打不破内心的“天花板”'],
]
#中文分析
X, Y = [lcut(i[1]) for i in data], [i[0] for i in data]
#划分训练集和预测集
X_train, X_test, y_train, y_test = train_test_split(X, Y)
#print(X_train)
print(len(X_train), len(X_test))
print(len(y_train), len(y_test))
"""['三星', '刚刚', '更新', '了', '自家', '的', '可', '穿戴', '设备', 'APP']"""
#--------------------------------Word2Vec词向量-------------------------------
word2vec = Word2Vec(X_train, size=max_features, min_count=1) #最大特征 最低过滤频次1
print(word2vec)
#映射特征词
w2i = {w:i for i, w in enumerate(word2vec.wv.index2word)}
print("【显示词语】")
print(word2vec.wv.index2word)
print(w2i)
"""['小米', '三星', '是', '维生素', '蛋白质', '及', 'APP', '氨基酸',..."""
"""{',': 0, '的': 1, '小米': 2, '、': 3, '华为': 4, ....}"""
#词向量计算
vectors = word2vec.wv.vectors
print("【词向量矩阵】")
print(vectors.shape)
print(vectors)
#自定义函数-获取词向量
def w2v(w):
i = w2i.get(w)
return vectors[i] if i else zeros(max_features)
#自定义函数-序列预处理
def pad(ls_of_words):
a = [[w2v(i) for i in x] for x in ls_of_words]
a = pad_sequences(a, maxlen, dtype='float')
return a
#序列化处理 转换为词向量
X_train, X_test = pad(X_train), pad(X_test)
print(X_train.shape)
print(X_test.shape)
"""(15, 40, 20) 15个样本 40个特征 每个特征用20词向量表示"""
#拉直形状 (15, 40, 20)=>(15, 40*20) (6, 40, 20)=>(6, 40*20)
X_train = X_train.reshape(len(y_train), maxlen*max_features)
X_test = X_test.reshape(len(y_test), maxlen*max_features)
print(X_train.shape)
print(X_test.shape)
#--------------------------------建模与训练-------------------------------
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
#调用GaussianNB分类器
clf = GaussianNB().fit(X_train, y_train)
pre = clf.predict(X_test)
print("预测结果:", pre)
print("真实结果:", y_test)
print(classification_report(y_test, pre))输出结果如下所示:
- 6个预测数据的accuracy ===> 0.83
15 6
15 6
Word2Vec(vocab=126, size=20, alpha=0.025)
【显示词语】
[',', '、', '小米', '的', '华为', '手机', '苹果', '维生素', 'APP', '官方', 'Linux', ... '安卓三大', '旗舰']
{',': 0, '、': 1, '小米': 2, '的': 3, '华为': 4, '手机': 5, '苹果': 6, ..., '安卓三大': 124, '旗舰': 125}
【词向量矩阵】
(126, 20)
[[ 0.02041552 -0.00929706 -0.00743623 ... -0.00246041 -0.00825108
0.02341811]
[-0.00256093 -0.01301112 -0.00697959 ... -0.00449076 -0.00551124
-0.00240511]
[ 0.01535473 0.01690796 -0.00262145 ... -0.01624218 0.00871249
-0.01159615]
...
[ 0.00631155 0.00369085 -0.00382834 ... 0.02468265 0.00945442
-0.0155745 ]
[-0.01198495 0.01711261 0.01097644 ... 0.01003117 0.01074963
0.01960118]
[ 0.00450704 -0.01114052 0.0186879 ... 0.00804681 0.01060277
0.01836049]]
(15, 40, 20)
(6, 40, 20)
(15, 800)
(6, 800)
预测结果: [1 1 1 0 1 0]
真实结果: [0, 1, 1, 0, 1, 0]
precision recall f1-score support
0 1.00 0.67 0.80 3
1 0.75 1.00 0.86 3
accuracy 0.83 6
macro avg 0.88 0.83 0.83 6
weighted avg 0.88 0.83 0.83 6三.Keras实现RNN文本分类
1.IMDB数据集和序列预处理
(1) IMDB数据集
Keras框架为我们提供了一些常用的内置数据集。比如,图像识别领域的手写识别MNIST数据集、文本分类领域的电影影评imdb数据集等等。这些数据库可以用一条代码就可以调用:
- (trainX, trainY), (testX, testY) = imdb.load_data(path=“imdb.npz”, num_words=max_features)
这些数据集是通过https://s3.amazonaws.com进行下载的,但有时该网站不能使用,需要下载数据至本地,再进行调用分析。Keras数据集百度云链接:
- 百度网盘 请输入提取码,提取码: 3a2u
作者将下载后的数据放在C:\Users\Administrator.keras\datasets文件夹下,如下图所示。
该数据集是互联网电影资料库(Internet Movie Database,简称IMDb),它是一个关于电影演员、电影、电视节目、电视明星和电影制作的在线数据库。
imdb.npz文件中数据和格式如下:
[list([1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, ...])
list([1, 194, 1153, 194, 8255, 78, 228, 5, 6, 1463, 4369, 5012, 134, 26, 4, 715, 8, 118, 1634, 14, 394, 20, 13, 119, 954, 189, 102, 5, 207, 110, 3103, 21, 14, 69, ...])
list([1, 14, 47, 8, 30, 31, 7, 4, 249, 108, 7, 4, 5974, 54, 61, 369, 13, 71, 149, 14, 22, 112, 4, 2401, 311, 12, 16, 3711, 33, 75, 43, 1829, 296, 4, 86, 320, 35, ...])
...
list([1, 11, 6, 230, 245, 6401, 9, 6, 1225, 446, 2, 45, 2174, 84, 8322, 4007, 21, 4, 912, 84, 14532, 325, 725, 134, 15271, 1715, 84, 5, 36, 28, 57, 1099, 21, 8, 140, ...])
list([1, 1446, 7079, 69, 72, 3305, 13, 610, 930, 8, 12, 582, 23, 5, 16, 484, 685, 54, 349, 11, 4120, 2959, 45, 58, 1466, 13, 197, 12, 16, 43, 23, 2, 5, 62, 30, 145, ...])
list([1, 17, 6, 194, 337, 7, 4, 204, 22, 45, 254, 8, 106, 14, 123, 4, 12815, 270, 14437, 5, 16923, 12255, 732, 2098, 101, 405, 39, 14, 1034, 4, 1310, 9, 115, 50, 305, ...])] train sequences每个list是一个句子,句子中每个数字表示单词的编号。那么,怎么获取编号对应的单词?此时需要使用imdb_word_index.json文件,其文件格式如下:
{"fawn": 34701, "tsukino": 52006,..., "paget": 18509, "expands": 20597}共有88584个单词,采用key-value格式存放,key代表单词,value代表(单词)编号。词频(单词在语料中出现次数)越高编号越小,例如, “the:1”出现次数最高,编号为1。
(2) 序列预处理
在进行深度学习向量转换过程中,通常需要使用pad_sequences()序列填充。其基本用法如下:
keras.preprocessing.sequence.pad_sequences(
sequences,
maxlen=None,
dtype='int32',
padding='pre',
truncating='pre',
value=0.
)参数含义如下:
- sequences:浮点数或整数构成的两层嵌套列表
- maxlen:None或整数,为序列的最大长度。大于此长度的序列将被截短,小于此长度的序列将在后部填0
- dtype:返回的numpy array的数据类型
- padding:pre或post,确定当需要补0时,在序列的起始还是结尾补0
- truncating:pre或post,确定当需要截断序列时,从起始还是结尾截断
- value:浮点数,此值将在填充时代替默认的填充值0
- 返回值是个2维张量,长度为maxlen
基本用法如下所示:
from keras.preprocessing.sequence import pad_sequences
print(pad_sequences([[1, 2, 3], [1]], maxlen=2))
"""[[2 3] [0 1]]"""
print(pad_sequences([[1, 2, 3], [1]], maxlen=3, value=9))
"""[[1 2 3] [9 9 1]]"""
print(pad_sequences([[2,3,4]], maxlen=10))
"""[[0 0 0 0 0 0 0 2 3 4]]"""
print(pad_sequences([[1,2,3,4,5],[6,7]], maxlen=10))
"""[[0 0 0 0 0 1 2 3 4 5] [0 0 0 0 0 0 0 0 6 7]]"""
print(pad_sequences([[1, 2, 3], [1]], maxlen=2, padding='post'))
"""结束位置补: [[2 3] [1 0]]"""
print(pad_sequences([[1, 2, 3], [1]], maxlen=4, truncating='post'))
"""起始位置补: [[0 1 2 3] [0 0 0 1]]""" 在自然语言中一般和分词器一起使用。
>>> tokenizer.texts_to_sequences(["下 雨 我 加班"])
[[4, 5, 6, 7]]
>>> keras.preprocessing.sequence.pad_sequences(tokenizer.texts_to_sequences(["下 雨 我 加班"]), maxlen=20)
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 5, 6, 7]],dtype=int32)2.词嵌入模型训练
此时我们将通过词嵌入模型进行训练,具体流程包括:
- 导入IMDB数据集
- 数据集转换为序列
- 创建Embedding词嵌入模型
- 神经网络训练
完整代码如下:
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 28 17:08:28 2020
@author: Eastmount CSDN
"""
from keras.datasets import imdb #Movie Database
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Flatten, Embedding
#-----------------------------------定义参数-----------------------------------
max_features = 20000 #按词频大小取样本前20000个词
input_dim = max_features #词库大小 必须>=max_features
maxlen = 80 #句子最大长度
batch_size = 128 #batch数量
output_dim = 40 #词向量维度
epochs = 2 #训练批次
#--------------------------------载入数据及预处理-------------------------------
#数据获取
(trainX, trainY), (testX, testY) = imdb.load_data(path="imdb.npz", num_words=max_features)
print(trainX.shape, trainY.shape) #(25000,) (25000,)
print(testX.shape, testY.shape) #(25000,) (25000,)
#序列截断或补齐为等长
trainX = sequence.pad_sequences(trainX, maxlen=maxlen)
testX = sequence.pad_sequences(testX, maxlen=maxlen)
print('trainX shape:', trainX.shape)
print('testX shape:', testX.shape)
#------------------------------------创建模型------------------------------------
model = Sequential()
#词嵌入:词库大小、词向量维度、固定序列长度
model.add(Embedding(input_dim, output_dim, input_length=maxlen))
#平坦化: maxlen*output_dim
model.add(Flatten())
#输出层: 2分类
model.add(Dense(units=1, activation='sigmoid'))
#RMSprop优化器 二元交叉熵损失
model.compile('rmsprop', 'binary_crossentropy', ['acc'])
#训练
model.fit(trainX, trainY, batch_size, epochs)
#模型可视化
model.summary()输出结果如下所示:
(25000,) (25000,)
(25000,) (25000,)
trainX shape: (25000, 80)
testX shape: (25000, 80)
Epoch 1/2
25000/25000 [==============================] - 2s 98us/step - loss: 0.6111 - acc: 0.6956
Epoch 2/2
25000/25000 [==============================] - 2s 69us/step - loss: 0.3578 - acc: 0.8549
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 80, 40) 800000
_________________________________________________________________
flatten_2 (Flatten) (None, 3200) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 3201
=================================================================
Total params: 803,201
Trainable params: 803,201
Non-trainable params: 0
_________________________________________________________________显示矩阵如下图所示:
3.RNN文本分类
RNN对IMDB电影数据集进行文本分类的完整代码如下所示:
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 28 17:08:28 2020
@author: Eastmount CSDN
"""
from keras.datasets import imdb #Movie Database
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Flatten, Embedding
from keras.layers import SimpleRNN
#-----------------------------------定义参数-----------------------------------
max_features = 20000 #按词频大小取样本前20000个词
input_dim = max_features #词库大小 必须>=max_features
maxlen = 40 #句子最大长度
batch_size = 128 #batch数量
output_dim = 40 #词向量维度
epochs = 3 #训练批次
units = 32 #RNN神经元数量
#--------------------------------载入数据及预处理-------------------------------
#数据获取
(trainX, trainY), (testX, testY) = imdb.load_data(path="imdb.npz", num_words=max_features)
print(trainX.shape, trainY.shape) #(25000,) (25000,)
print(testX.shape, testY.shape) #(25000,) (25000,)
#序列截断或补齐为等长
trainX = sequence.pad_sequences(trainX, maxlen=maxlen)
testX = sequence.pad_sequences(testX, maxlen=maxlen)
print('trainX shape:', trainX.shape)
print('testX shape:', testX.shape)
#-----------------------------------创建RNN模型-----------------------------------
model = Sequential()
#词嵌入 词库大小、词向量维度、固定序列长度
model.add(Embedding(input_dim, output_dim, input_length=maxlen))
#RNN Cell
model.add(SimpleRNN(units, return_sequences=True)) #返回序列全部结果
model.add(SimpleRNN(units, return_sequences=False)) #返回序列最尾结果
#输出层 2分类
model.add(Dense(units=1, activation='sigmoid'))
#模型可视化
model.summary()
#-----------------------------------建模与训练-----------------------------------
#激活神经网络
model.compile(optimizer = 'rmsprop', #RMSprop优化器
loss = 'binary_crossentropy', #二元交叉熵损失
metrics = ['accuracy'] #计算误差或准确率
)
#训练
history = model.fit(trainX,
trainY,
batch_size=batch_size,
epochs=epochs,
verbose=2,
validation_split=.1 #取10%样本作验证
)
#-----------------------------------预测与可视化-----------------------------------
import matplotlib.pyplot as plt
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']
plt.plot(range(epochs), accuracy)
plt.plot(range(epochs), val_accuracy)
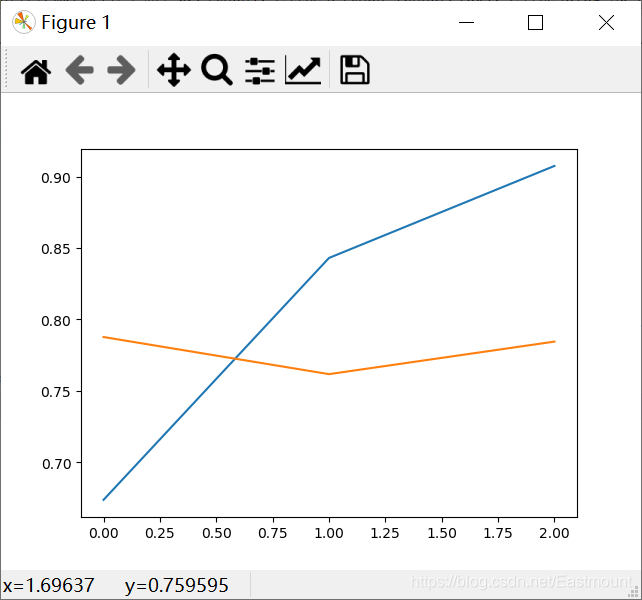
plt.show()输出结果如下所示,三个Epoch训练。
- 训练数据的accuracy ===> 0.9075
- 评估数据的val_accuracy ===> 0.7844
Epoch可以用下图进行形象的表示。
(25000,) (25000,)
(25000,) (25000,)
trainX shape: (25000, 40)
testX shape: (25000, 40)
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 40, 40) 800000
_________________________________________________________________
simple_rnn_3 (SimpleRNN) (None, 40, 32) 2336
_________________________________________________________________
simple_rnn_4 (SimpleRNN) (None, 32) 2080
_________________________________________________________________
dense_2 (Dense) (None, 1) 33
=================================================================
Total params: 804,449
Trainable params: 804,449
Non-trainable params: 0
_________________________________________________________________
Train on 22500 samples, validate on 2500 samples
Epoch 1/3
- 11s - loss: 0.5741 - accuracy: 0.6735 - val_loss: 0.4462 - val_accuracy: 0.7876
Epoch 2/3
- 14s - loss: 0.3572 - accuracy: 0.8430 - val_loss: 0.4928 - val_accuracy: 0.7616
Epoch 3/3
- 12s - loss: 0.2329 - accuracy: 0.9075 - val_loss: 0.5050 - val_accuracy: 0.7844绘制的accuracy和val_accuracy曲线如下图所示:
- loss: 0.2329 - accuracy: 0.9075 - val_loss: 0.5050 - val_accuracy: 0.7844
四.RNN实现中文数据集的文本分类
1.RNN+Word2Vector文本分类
第一步,导入文本数据集并转换为词向量。
data = [
[0, '小米粥是以小米作为主要食材熬制而成的粥,口味清淡,清香味,具有简单易制,健胃消食的特点'],
[0, '煮粥时一定要先烧开水然后放入洗净后的小米'],
[0, '蛋白质及氨基酸、脂肪、维生素、矿物质'],
[0, '小米是传统健康食品,可单独焖饭和熬粥'],
[0, '苹果,是水果中的一种'],
[0, '粥的营养价值很高,富含矿物质和维生素,含钙量丰富,有助于代谢掉体内多余盐分'],
[0, '鸡蛋有很高的营养价值,是优质蛋白质、B族维生素的良好来源,还能提供脂肪、维生素和矿物质'],
[0, '这家超市的苹果都非常新鲜'],
[0, '在北方小米是主要食物之一,很多地区有晚餐吃小米粥的习俗'],
[0, '小米营养价值高,营养全面均衡 ,主要含有碳水化合物'],
[0, '蛋白质及氨基酸、脂肪、维生素、盐分'],
[1, '小米、三星、华为,作为安卓三大手机旗舰'],
[1, '别再管小米华为了!魅族手机再曝光:这次真的完美了'],
[1, '苹果手机或将重陷2016年困境,但这次它无法再大幅提价了'],
[1, '三星想要继续压制华为,仅凭A70还不够'],
[1, '三星手机屏占比将再创新高,超华为及苹果旗舰'],
[1, '华为P30、三星A70爆卖,斩获苏宁最佳手机营销奖'],
[1, '雷军,用一张图告诉你:小米和三星的差距在哪里'],
[1, '小米米聊APP官方Linux版上线,适配深度系统'],
[1, '三星刚刚更新了自家的可穿戴设备APP'],
[1, '华为、小米跨界并不可怕,可怕的打不破内心的“天花板”'],
]
#中文分析
X, Y = [lcut(i[1]) for i in data], [i[0] for i in data]
#划分训练集和预测集
X_train, X_test, y_train, y_test = train_test_split(X, Y)
#print(X_train)
print(len(X_train), len(X_test))
print(len(y_train), len(y_test))
"""['三星', '刚刚', '更新', '了', '自家', '的', '可', '穿戴', '设备', 'APP']"""
#--------------------------------Word2Vec词向量-------------------------------
word2vec = Word2Vec(X_train, size=max_features, min_count=1) #最大特征 最低过滤频次1
print(word2vec)
#映射特征词
w2i = {w:i for i, w in enumerate(word2vec.wv.index2word)}
print("【显示词语】")
print(word2vec.wv.index2word)
print(w2i)
"""['小米', '三星', '是', '维生素', '蛋白质', '及', 'APP', '氨基酸',..."""
"""{',': 0, '的': 1, '小米': 2, '、': 3, '华为': 4, ....}"""
#词向量计算
vectors = word2vec.wv.vectors
print("【词向量矩阵】")
print(vectors.shape)
print(vectors)
#自定义函数-获取词向量
def w2v(w):
i = w2i.get(w)
return vectors[i] if i else zeros(max_features)
#自定义函数-序列预处理
def pad(ls_of_words):
a = [[w2v(i) for i in x] for x in ls_of_words]
a = pad_sequences(a, maxlen, dtype='float')
return a
#序列化处理 转换为词向量
X_train, X_test = pad(X_train), pad(X_test)此时输出结果如下所示:
15 6
15 6
Word2Vec(vocab=120, size=20, alpha=0.025)
【显示词语】
[',', '的', '、', '小米', '三星', '是', '维生素', '蛋白质', '及',
'脂肪', '华为', '苹果', '可', 'APP', '氨基酸', '在', '手机', '旗舰',
'矿物质', '主要', '有', '小米粥', '作为', '刚刚', '更新', '设备', ...]
{',': 0, '的': 1, '、': 2, '小米': 3, '三星': 4, '是': 5,
'维生素': 6, '蛋白质': 7, '及': 8, '脂肪': 9, '和': 10,
'华为': 11, '苹果': 12, '可': 13, 'APP': 14, '氨基酸': 15, ...}
【词向量矩阵】
(120, 20)
[[ 0.00219526 0.00936278 0.00390177 ... -0.00422463 0.01543128
0.02481441]
[ 0.02346811 -0.01520025 -0.00563479 ... -0.01656673 -0.02222313
0.00438196]
[-0.02253242 -0.01633896 -0.02209039 ... 0.01301584 -0.01016752
0.01147605]
...
[ 0.01793107 0.01912305 -0.01780855 ... -0.00109831 0.02460653
-0.00023512]
[-0.00599797 0.02155897 -0.01874896 ... 0.00149929 0.00200266
0.00988515]
[ 0.0050361 -0.00848463 -0.0235001 ... 0.01531716 -0.02348576
0.01051775]]第二步,建立RNN神经网络结构,使用Bi-GRU模型,并进行训练与预测。
#--------------------------------建模与训练-------------------------------
model = Sequential()
#双向RNN
model.add(Bidirectional(GRU(units), input_shape=(maxlen, max_features)))
#输出层 2分类
model.add(Dense(units=1, activation='sigmoid'))
#模型可视化
model.summary()
#激活神经网络
model.compile(optimizer = 'rmsprop', #RMSprop优化器
loss = 'binary_crossentropy', #二元交叉熵损失
metrics = ['acc'] #计算误差或准确率
)
#训练
history = model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs,
verbose=verbose, validation_data=(X_test, y_test))
#----------------------------------预测与可视化------------------------------
#预测
score = model.evaluate(X_test, y_test, batch_size=batch_size)
print('test loss:', score[0])
print('test accuracy:', score[1])
#可视化
acc = history.history['acc']
val_acc = history.history['val_acc']
# 设置类标
plt.xlabel("Iterations")
plt.ylabel("Accuracy")
#绘图
plt.plot(range(epochs), acc, "bo-", linewidth=2, markersize=12, label="accuracy")
plt.plot(range(epochs), val_acc, "gs-", linewidth=2, markersize=12, label="val_accuracy")
plt.legend(loc="upper left")
plt.title("RNN-Word2vec")
plt.show()输出结果如下图所示,发现accuracy和val_accuracy值非常不理想。怎么解决呢?
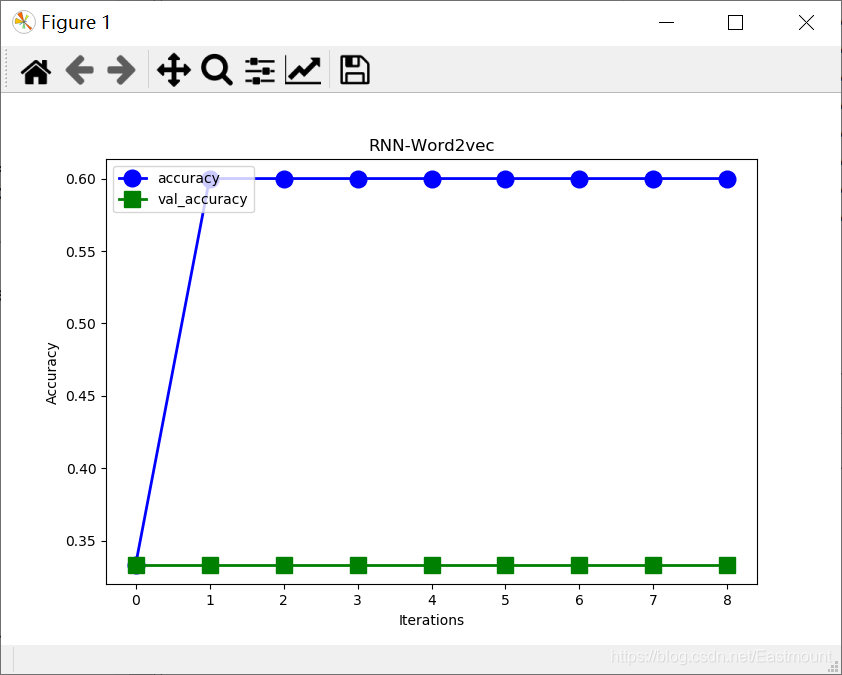
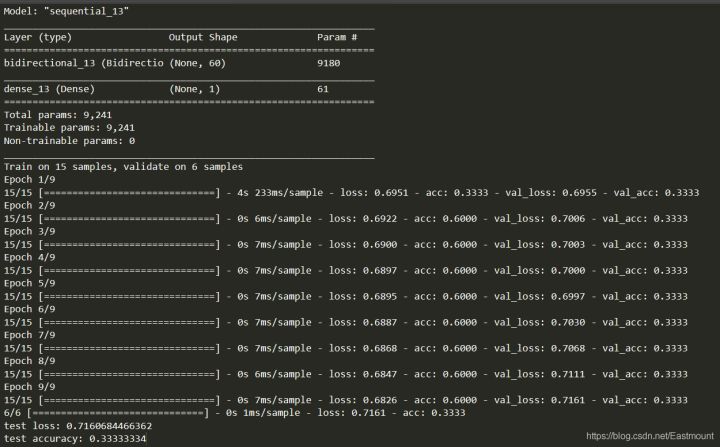
神经网络模型和Epoch训练结果如下图所示:
- test loss: 0.7160684466362
- test accuracy: 0.33333334
这里补充一个知识点——EarlyStopping。
EarlyStopping是Callbacks的一种,callbacks用于指定在每个epoch开始和结束的时候进行哪种特定操作。Callbacks中有一些设置好的接口,可以直接使用,如acc、val_acc、loss和val_loss等。EarlyStopping则是用于提前停止训练的callbacks,可以达到当训练集上的loss不在减小(即减小的程度小于某个阈值)的时候停止继续训练。上面程序中,当我们loss不在减小时就可以调用Callbacks停止训练。
推荐文章:[深度学习] keras的EarlyStopping使用与技巧 - zwqjoy
最后给出该部分的完整代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 28 22:10:20 2020
@author: Eastmount CSDN
"""
from jieba import lcut
from numpy import zeros
import matplotlib.pyplot as plt
from gensim.models import Word2Vec
from sklearn.model_selection import train_test_split
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense, GRU, Bidirectional
from tensorflow.python.keras.callbacks import EarlyStopping
#-----------------------------------定义参数----------------------------------
max_features = 20 #词向量维度
units = 30 #RNN神经元数量
maxlen = 40 #序列最大长度
epochs = 9 #训练最大轮数
batch_size = 12 #每批数据量大小
verbose = 1 #训练过程展示
patience = 1 #没有进步的训练轮数
callbacks = [EarlyStopping('val_acc', patience=patience)]
#--------------------------------载入数据及预处理-------------------------------
data = [
[0, '小米粥是以小米作为主要食材熬制而成的粥,口味清淡,清香味,具有简单易制,健胃消食的特点'],
[0, '煮粥时一定要先烧开水然后放入洗净后的小米'],
[0, '蛋白质及氨基酸、脂肪、维生素、矿物质'],
[0, '小米是传统健康食品,可单独焖饭和熬粥'],
[0, '苹果,是水果中的一种'],
[0, '粥的营养价值很高,富含矿物质和维生素,含钙量丰富,有助于代谢掉体内多余盐分'],
[0, '鸡蛋有很高的营养价值,是优质蛋白质、B族维生素的良好来源,还能提供脂肪、维生素和矿物质'],
[0, '这家超市的苹果都非常新鲜'],
[0, '在北方小米是主要食物之一,很多地区有晚餐吃小米粥的习俗'],
[0, '小米营养价值高,营养全面均衡 ,主要含有碳水化合物'],
[0, '蛋白质及氨基酸、脂肪、维生素、盐分'],
[1, '小米、三星、华为,作为安卓三大手机旗舰'],
[1, '别再管小米华为了!魅族手机再曝光:这次真的完美了'],
[1, '苹果手机或将重陷2016年困境,但这次它无法再大幅提价了'],
[1, '三星想要继续压制华为,仅凭A70还不够'],
[1, '三星手机屏占比将再创新高,超华为及苹果旗舰'],
[1, '华为P30、三星A70爆卖,斩获苏宁最佳手机营销奖'],
[1, '雷军,用一张图告诉你:小米和三星的差距在哪里'],
[1, '小米米聊APP官方Linux版上线,适配深度系统'],
[1, '三星刚刚更新了自家的可穿戴设备APP'],
[1, '华为、小米跨界并不可怕,可怕的打不破内心的“天花板”'],
]
#中文分析
X, Y = [lcut(i[1]) for i in data], [i[0] for i in data]
#划分训练集和预测集
X_train, X_test, y_train, y_test = train_test_split(X, Y)
#print(X_train)
print(len(X_train), len(X_test))
print(len(y_train), len(y_test))
"""['三星', '刚刚', '更新', '了', '自家', '的', '可', '穿戴', '设备', 'APP']"""
#--------------------------------Word2Vec词向量-------------------------------
word2vec = Word2Vec(X_train, size=max_features, min_count=1) #最大特征 最低过滤频次1
print(word2vec)
#映射特征词
w2i = {w:i for i, w in enumerate(word2vec.wv.index2word)}
print("【显示词语】")
print(word2vec.wv.index2word)
print(w2i)
"""['小米', '三星', '是', '维生素', '蛋白质', '及', 'APP', '氨基酸',..."""
"""{',': 0, '的': 1, '小米': 2, '、': 3, '华为': 4, ....}"""
#词向量计算
vectors = word2vec.wv.vectors
print("【词向量矩阵】")
print(vectors.shape)
print(vectors)
#自定义函数-获取词向量
def w2v(w):
i = w2i.get(w)
return vectors[i] if i else zeros(max_features)
#自定义函数-序列预处理
def pad(ls_of_words):
a = [[w2v(i) for i in x] for x in ls_of_words]
a = pad_sequences(a, maxlen, dtype='float')
return a
#序列化处理 转换为词向量
X_train, X_test = pad(X_train), pad(X_test)
#--------------------------------建模与训练-------------------------------
model = Sequential()
#双向RNN
model.add(Bidirectional(GRU(units), input_shape=(maxlen, max_features)))
#输出层 2分类
model.add(Dense(units=1, activation='sigmoid'))
#模型可视化
model.summary()
#激活神经网络
model.compile(optimizer = 'rmsprop', #RMSprop优化器
loss = 'binary_crossentropy', #二元交叉熵损失
metrics = ['acc'] #计算误差或准确率
)
#训练
history = model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs,
verbose=verbose, validation_data=(X_test, y_test))
#----------------------------------预测与可视化------------------------------
#预测
score = model.evaluate(X_test, y_test, batch_size=batch_size)
print('test loss:', score[0])
print('test accuracy:', score[1])
#可视化
acc = history.history['acc']
val_acc = history.history['val_acc']
# 设置类标
plt.xlabel("Iterations")
plt.ylabel("Accuracy")
#绘图
plt.plot(range(epochs), acc, "bo-", linewidth=2, markersize=12, label="accuracy")
plt.plot(range(epochs), val_acc, "gs-", linewidth=2, markersize=12, label="val_accuracy")
plt.legend(loc="upper left")
plt.title("RNN-Word2vec")
plt.show()2.LSTM+Word2Vec文本分类
接着我们使用LSTM和Word2Vec进行文本分类。整个神经网络的结构很简单,第一层是嵌入层,将文本中的单词转化为向量;之后经过一层LSTM层,使用LSTM中最后一个时刻的隐藏状态;再接一个全连接层,即可完成整个网络的构造。
注意矩阵形状的变换。
- X_train = X_train.reshape(len(y_train), maxlen*max_features)
- X_test = X_test.reshape(len(y_test), maxlen*max_features)
完整代码如下所示:
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 28 22:10:20 2020
@author: Eastmount CSDN
"""
from jieba import lcut
from numpy import zeros
import matplotlib.pyplot as plt
from gensim.models import Word2Vec
from sklearn.model_selection import train_test_split
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense, LSTM, GRU, Embedding
from tensorflow.python.keras.callbacks import EarlyStopping
#-----------------------------------定义参数----------------------------------
max_features = 20 #词向量维度
units = 30 #RNN神经元数量
maxlen = 40 #序列最大长度
epochs = 9 #训练最大轮数
batch_size = 12 #每批数据量大小
verbose = 1 #训练过程展示
patience = 1 #没有进步的训练轮数
callbacks = [EarlyStopping('val_acc', patience=patience)]
#--------------------------------载入数据及预处理-------------------------------
data = [
[0, '小米粥是以小米作为主要食材熬制而成的粥,口味清淡,清香味,具有简单易制,健胃消食的特点'],
[0, '煮粥时一定要先烧开水然后放入洗净后的小米'],
[0, '蛋白质及氨基酸、脂肪、维生素、矿物质'],
[0, '小米是传统健康食品,可单独焖饭和熬粥'],
[0, '苹果,是水果中的一种'],
[0, '粥的营养价值很高,富含矿物质和维生素,含钙量丰富,有助于代谢掉体内多余盐分'],
[0, '鸡蛋有很高的营养价值,是优质蛋白质、B族维生素的良好来源,还能提供脂肪、维生素和矿物质'],
[0, '这家超市的苹果都非常新鲜'],
[0, '在北方小米是主要食物之一,很多地区有晚餐吃小米粥的习俗'],
[0, '小米营养价值高,营养全面均衡 ,主要含有碳水化合物'],
[0, '蛋白质及氨基酸、脂肪、维生素、盐分'],
[1, '小米、三星、华为,作为安卓三大手机旗舰'],
[1, '别再管小米华为了!魅族手机再曝光:这次真的完美了'],
[1, '苹果手机或将重陷2016年困境,但这次它无法再大幅提价了'],
[1, '三星想要继续压制华为,仅凭A70还不够'],
[1, '三星手机屏占比将再创新高,超华为及苹果旗舰'],
[1, '华为P30、三星A70爆卖,斩获苏宁最佳手机营销奖'],
[1, '雷军,用一张图告诉你:小米和三星的差距在哪里'],
[1, '小米米聊APP官方Linux版上线,适配深度系统'],
[1, '三星刚刚更新了自家的可穿戴设备APP'],
[1, '华为、小米跨界并不可怕,可怕的打不破内心的“天花板”'],
]
#中文分析
X, Y = [lcut(i[1]) for i in data], [i[0] for i in data]
#划分训练集和预测集
X_train, X_test, y_train, y_test = train_test_split(X, Y)
#print(X_train)
print(len(X_train), len(X_test))
print(len(y_train), len(y_test))
"""['三星', '刚刚', '更新', '了', '自家', '的', '可', '穿戴', '设备', 'APP']"""
#--------------------------------Word2Vec词向量-------------------------------
word2vec = Word2Vec(X_train, size=max_features, min_count=1) #最大特征 最低过滤频次1
print(word2vec)
#映射特征词
w2i = {w:i for i, w in enumerate(word2vec.wv.index2word)}
print("【显示词语】")
print(word2vec.wv.index2word)
print(w2i)
"""['小米', '三星', '是', '维生素', '蛋白质', '及', 'APP', '氨基酸',..."""
"""{',': 0, '的': 1, '小米': 2, '、': 3, '华为': 4, ....}"""
#词向量计算
vectors = word2vec.wv.vectors
print("【词向量矩阵】")
print(vectors.shape)
print(vectors)
#自定义函数-获取词向量
def w2v(w):
i = w2i.get(w)
return vectors[i] if i else zeros(max_features)
#自定义函数-序列预处理
def pad(ls_of_words):
a = [[w2v(i) for i in x] for x in ls_of_words]
a = pad_sequences(a, maxlen, dtype='float')
return a
#序列化处理 转换为词向量
X_train, X_test = pad(X_train), pad(X_test)
print(X_train.shape)
print(X_test.shape)
"""(15, 40, 20) 15个样本 40个特征 每个特征用20词向量表示"""
#拉直形状 (15, 40, 20)=>(15, 40*20) (6, 40, 20)=>(6, 40*20)
X_train = X_train.reshape(len(y_train), maxlen*max_features)
X_test = X_test.reshape(len(y_test), maxlen*max_features)
#--------------------------------建模与训练-------------------------------
model = Sequential()
#构建Embedding层 128代表Embedding层的向量维度
model.add(Embedding(max_features, 128))
#构建LSTM层
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
#构建全连接层
#注意上面构建LSTM层时只会得到最后一个节点的输出,如果需要输出每个时间点的结果需将return_sequences=True
model.add(Dense(units=1, activation='sigmoid'))
#模型可视化
model.summary()
#激活神经网络
model.compile(optimizer = 'rmsprop', #RMSprop优化器
loss = 'binary_crossentropy', #二元交叉熵损失
metrics = ['acc'] #计算误差或准确率
)
#训练
history = model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs,
verbose=verbose, validation_data=(X_test, y_test))
#----------------------------------预测与可视化------------------------------
#预测
score = model.evaluate(X_test, y_test, batch_size=batch_size)
print('test loss:', score[0])
print('test accuracy:', score[1])
#可视化
acc = history.history['acc']
val_acc = history.history['val_acc']
# 设置类标
plt.xlabel("Iterations")
plt.ylabel("Accuracy")
#绘图
plt.plot(range(epochs), acc, "bo-", linewidth=2, markersize=12, label="accuracy")
plt.plot(range(epochs), val_acc, "gs-", linewidth=2, markersize=12, label="val_accuracy")
plt.legend(loc="upper left")
plt.title("LSTM-Word2vec")
plt.show()输出结果如下所示,仍然不理想。
- test loss: 0.712007462978363
- test accuracy: 0.33333334
Model: "sequential_22"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_8 (Embedding) (None, None, 128) 2560
_________________________________________________________________
lstm_8 (LSTM) (None, 128) 131584
_________________________________________________________________
dense_21 (Dense) (None, 1) 129
=================================================================
Total params: 134,273
Trainable params: 134,273
Non-trainable params: 0
_________________________________________________________________
Train on 15 samples, validate on 6 samples
Epoch 1/9
15/15 [==============================] - 8s 552ms/sample - loss: 0.6971 - acc: 0.5333 - val_loss: 0.6911 - val_acc: 0.6667
Epoch 2/9
15/15 [==============================] - 5s 304ms/sample - loss: 0.6910 - acc: 0.7333 - val_loss: 0.7111 - val_acc: 0.3333
Epoch 3/9
15/15 [==============================] - 3s 208ms/sample - loss: 0.7014 - acc: 0.4667 - val_loss: 0.7392 - val_acc: 0.3333
Epoch 4/9
15/15 [==============================] - 4s 261ms/sample - loss: 0.6890 - acc: 0.5333 - val_loss: 0.7471 - val_acc: 0.3333
Epoch 5/9
15/15 [==============================] - 4s 248ms/sample - loss: 0.6912 - acc: 0.5333 - val_loss: 0.7221 - val_acc: 0.3333
Epoch 6/9
15/15 [==============================] - 3s 210ms/sample - loss: 0.6857 - acc: 0.5333 - val_loss: 0.7143 - val_acc: 0.3333
Epoch 7/9
15/15 [==============================] - 3s 187ms/sample - loss: 0.6906 - acc: 0.5333 - val_loss: 0.7346 - val_acc: 0.3333
Epoch 8/9
15/15 [==============================] - 3s 185ms/sample - loss: 0.7066 - acc: 0.5333 - val_loss: 0.7578 - val_acc: 0.3333
Epoch 9/9
15/15 [==============================] - 4s 235ms/sample - loss: 0.7197 - acc: 0.5333 - val_loss: 0.7120 - val_acc: 0.3333
6/6 [==============================] - 0s 43ms/sample - loss: 0.7120 - acc: 0.3333
test loss: 0.712007462978363
test accuracy: 0.33333334对应的图形如下所示。
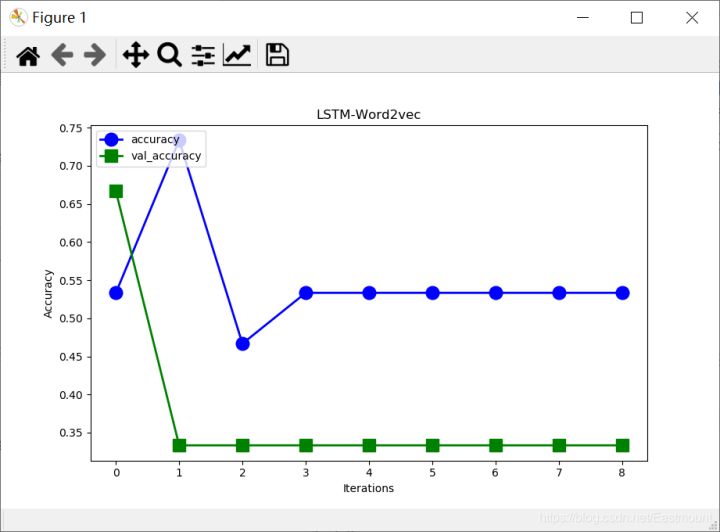
3.LSTM+TFIDF文本分类
同时,补充LSTM+TFIDF文本分类代码。
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 28 22:10:20 2020
@author: Eastmount CSDN
"""
from jieba import lcut
from numpy import zeros
import matplotlib.pyplot as plt
from gensim.models import Word2Vec
from sklearn.model_selection import train_test_split
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense, LSTM, GRU, Embedding
from tensorflow.python.keras.callbacks import EarlyStopping
#-----------------------------------定义参数----------------------------------
max_features = 20 #词向量维度
units = 30 #RNN神经元数量
maxlen = 40 #序列最大长度
epochs = 9 #训练最大轮数
batch_size = 12 #每批数据量大小
verbose = 1 #训练过程展示
patience = 1 #没有进步的训练轮数
callbacks = [EarlyStopping('val_acc', patience=patience)]
#--------------------------------载入数据及预处理-------------------------------
data = [
[0, '小米粥是以小米作为主要食材熬制而成的粥,口味清淡,清香味,具有简单易制,健胃消食的特点'],
[0, '煮粥时一定要先烧开水然后放入洗净后的小米'],
[0, '蛋白质及氨基酸、脂肪、维生素、矿物质'],
[0, '小米是传统健康食品,可单独焖饭和熬粥'],
[0, '苹果,是水果中的一种'],
[0, '粥的营养价值很高,富含矿物质和维生素,含钙量丰富,有助于代谢掉体内多余盐分'],
[0, '鸡蛋有很高的营养价值,是优质蛋白质、B族维生素的良好来源,还能提供脂肪、维生素和矿物质'],
[0, '这家超市的苹果都非常新鲜'],
[0, '在北方小米是主要食物之一,很多地区有晚餐吃小米粥的习俗'],
[0, '小米营养价值高,营养全面均衡 ,主要含有碳水化合物'],
[0, '蛋白质及氨基酸、脂肪、维生素、盐分'],
[1, '小米、三星、华为,作为安卓三大手机旗舰'],
[1, '别再管小米华为了!魅族手机再曝光:这次真的完美了'],
[1, '苹果手机或将重陷2016年困境,但这次它无法再大幅提价了'],
[1, '三星想要继续压制华为,仅凭A70还不够'],
[1, '三星手机屏占比将再创新高,超华为及苹果旗舰'],
[1, '华为P30、三星A70爆卖,斩获苏宁最佳手机营销奖'],
[1, '雷军,用一张图告诉你:小米和三星的差距在哪里'],
[1, '小米米聊APP官方Linux版上线,适配深度系统'],
[1, '三星刚刚更新了自家的可穿戴设备APP'],
[1, '华为、小米跨界并不可怕,可怕的打不破内心的“天花板”'],
]
#中文分词
X, Y = [' '.join(lcut(i[1])) for i in data], [i[0] for i in data]
print(X)
print(Y)
#['煮粥 时 一定 要 先烧 开水 然后 放入 洗净 后 的 小米', ...]
#--------------------------------------计算词频------------------------------------
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
#将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
#计算个词语出现的次数
X_data = vectorizer.fit_transform(X)
print(X_data)
#获取词袋中所有文本关键词
word = vectorizer.get_feature_names()
print('【查看单词】')
for w in word:
print(w, end = " ")
else:
print("\n")
#词频矩阵
print(X_data.toarray())
#将词频矩阵X统计成TF-IDF值
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X_data)
#查看数据结构 tfidf[i][j]表示i类文本中的tf-idf权重
weight = tfidf.toarray()
print(weight)
#数据集划分
X_train, X_test, y_train, y_test = train_test_split(weight, Y)
print(X_train.shape, X_test.shape)
print(len(y_train), len(y_test))
#(15, 117) (6, 117) 15 6
#--------------------------------建模与训练-------------------------------
model = Sequential()
#构建Embedding层 128代表Embedding层的向量维度
model.add(Embedding(max_features, 128))
#构建LSTM层
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
#构建全连接层
#注意上面构建LSTM层时只会得到最后一个节点的输出,如果需要输出每个时间点的结果需将return_sequences=True
model.add(Dense(units=1, activation='sigmoid'))
#模型可视化
model.summary()
#激活神经网络
model.compile(optimizer = 'rmsprop', #RMSprop优化器
loss = 'binary_crossentropy', #二元交叉熵损失
metrics = ['acc'] #计算误差或准确率
)
#训练
history = model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs,
verbose=verbose, validation_data=(X_test, y_test))
#----------------------------------预测与可视化------------------------------
#预测
score = model.evaluate(X_test, y_test, batch_size=batch_size)
print('test loss:', score[0])
print('test accuracy:', score[1])
#可视化
acc = history.history['acc']
val_acc = history.history['val_acc']
# 设置类标
plt.xlabel("Iterations")
plt.ylabel("Accuracy")
#绘图
plt.plot(range(epochs), acc, "bo-", linewidth=2, markersize=12, label="accuracy")
plt.plot(range(epochs), val_acc, "gs-", linewidth=2, markersize=12, label="val_accuracy")
plt.legend(loc="upper left")
plt.title("LSTM-TFIDF")
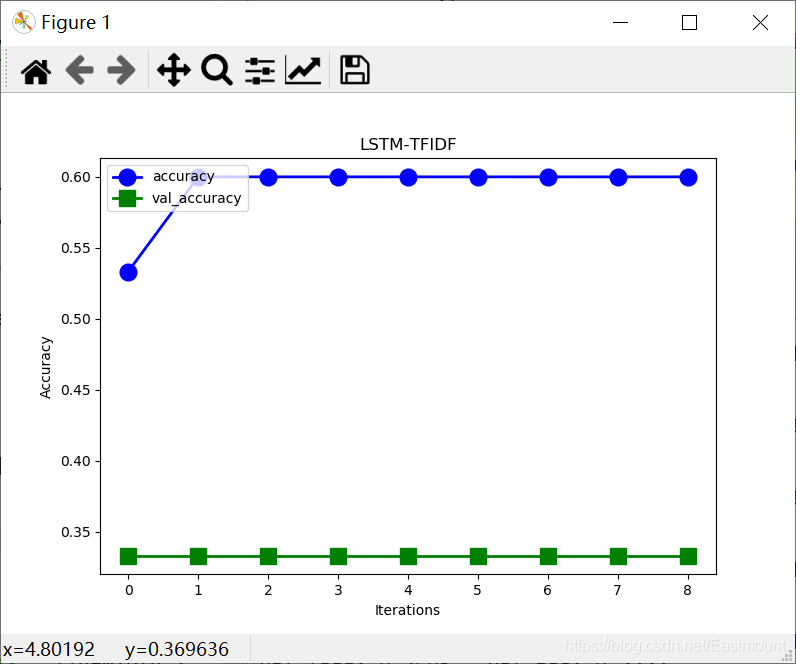
plt.show()输出结果如下所示:
- test loss: 0.7694947719573975
- test accuracy: 0.33333334
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, None, 128) 2560
_________________________________________________________________
lstm_1 (LSTM) (None, 128) 131584
_________________________________________________________________
dense_1 (Dense) (None, 1) 129
=================================================================
Total params: 134,273
Trainable params: 134,273
Non-trainable params: 0
_________________________________________________________________
Train on 15 samples, validate on 6 samples
Epoch 1/9
15/15 [==============================] - 2s 148ms/sample - loss: 0.6898 - acc: 0.5333 - val_loss: 0.7640 - val_acc: 0.3333
Epoch 2/9
15/15 [==============================] - 1s 48ms/sample - loss: 0.6779 - acc: 0.6000 - val_loss: 0.7773 - val_acc: 0.3333
Epoch 3/9
15/15 [==============================] - 1s 36ms/sample - loss: 0.6769 - acc: 0.6000 - val_loss: 0.7986 - val_acc: 0.3333
Epoch 4/9
15/15 [==============================] - 1s 47ms/sample - loss: 0.6722 - acc: 0.6000 - val_loss: 0.8097 - val_acc: 0.3333
Epoch 5/9
15/15 [==============================] - 1s 42ms/sample - loss: 0.7021 - acc: 0.6000 - val_loss: 0.7680 - val_acc: 0.3333
Epoch 6/9
15/15 [==============================] - 1s 36ms/sample - loss: 0.6890 - acc: 0.6000 - val_loss: 0.8147 - val_acc: 0.3333
Epoch 7/9
15/15 [==============================] - 1s 37ms/sample - loss: 0.6906 - acc: 0.6000 - val_loss: 0.8599 - val_acc: 0.3333
Epoch 8/9
15/15 [==============================] - 1s 43ms/sample - loss: 0.6819 - acc: 0.6000 - val_loss: 0.8303 - val_acc: 0.3333
Epoch 9/9
15/15 [==============================] - 1s 40ms/sample - loss: 0.6884 - acc: 0.6000 - val_loss: 0.7695 - val_acc: 0.3333
6/6 [==============================] - 0s 7ms/sample - loss: 0.7695 - acc: 0.3333
test loss: 0.7694947719573975
test accuracy: 0.33333334对应图形如下:
4.机器学习和深度学习对比分析
最终结果我们进行简单对比,发现机器学习比深度学习好,这是为什么呢?我们又能做哪些提升呢?
- MultinomialNB+TFIDF:test accuracy = 0.67
- GaussianNB+Word2Vec:test accuracy = 0.83
- RNN+Word2Vector:test accuracy = 0.33333334
- LSTM+Word2Vec:test accuracy = 0.33333334
- LSTM+TFIDF:test accuracy = 0.33333334
作者结合大佬们的文章及自己的经验对其进行简单分析,原因如下:
- 一是 数据集预处理的原因,上述代码没有进行停用词过滤,大量标点符号和停用词影响了文本分类效果。同时词向量的维度设置也需要进行调试。
- 二是 数据集大小的原因。数据量少的情况下,推荐使用CNN,RNN的过拟合会让你欲哭无泪。如果数据量多,也许RNN效果会更好。如果为了创新,RLSTM和RCNN等都是近几年不错的选择。但如果仅仅是为了应用,用普通的机器学习方法已经足够优秀了(特别是新闻数据集),如果考虑上时间成本,贝叶斯无疑才是真正的最好选择。
- 三是 CNN和RNN适用性不同。CNN擅长空间特征的学习和捕获,RNN擅长时序特征的捕获。从结构来讲,RNN更胜一筹。主流的NLP问题,比如翻译、生成文本,seq2seq(俩独立RNN)的引入突破了很多之前的benchmark。Attention的引入是为了解决长句问题,其本质就是外挂了额外的一个softmax去学词和词的映射关系,有点像外挂存储,其根源来自一篇名为“neural turing machine”的paper。
- 四是 不同的数据集适应不同的方法,各种方法各有所长。有的情感分析GRU好于CNN,而新闻分类、文本分类竞赛CNN可能会有优势。CNN具有速度优势,基本比较大的数据上CNN能加大参数,拟合更多种类的local phrase frequency,获得更好的效果。如果你是想做系统,两个算法又各有所长,就是ensemble登场的时候了。
- 五是 在文本情感分类领域,GRU是要好于CNN,并且随着句子长度的增长,GRU的这一优势会进一步放大。当句子的情感分类是由整个句子决定的时候,GRU会更容易分类正确, 当句子的情感分类是由几个局部的key-phrases决定的时候,CNN会更容易分类正确。
总之,我们在真实的实验中,尽量选择适合我们数据集的算法,这也是实验中的一部分,我们需要对比各种算法、各种参数、各种学习模型,从而找到一个更好的算法。后续作者会进一步学习TextCNN、Attention、BiLSTM、GAN等算法,希望能与大家一起进步。
参考文献:
再次感谢参考文献前辈和老师们的贡献,同时也参考了作者的Python人工智能和数据分析系列文章,源码请在github下载。
[1] Keras的imdb和MNIST数据集无法下载问题解决 - 摸金青年v
[2] 官网实例详解4.42(imdb.py)-keras学习笔记四 - wyx100
[3] Keras文本分类 - 强推基基伟老师文章
[4] TextCNN文本分类(keras实现)- 强推Asia-Lee老师的文章
[5] Keras之文本分类实现 - 强推知乎王奕磊老师的文章
[6 ]自然语言处理入门(二)–Keras实现BiLSTM+Attention新闻标题文本分类 - ilivecode
[7] 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 - 知乎清凇
[8] 基于 word2vec 和 CNN 的文本分类 :综述 & 实践 - 牛亚峰serena
[9] GitHub - keras-team/keras: Deep Learning for humans
[10] [深度学习] keras的EarlyStopping使用与技巧 - zwqjoy
[11] 深度学习为什么会出现validation accuracy大于train accuracy的现象?- ICOZ
[12] Keras实现CNN文本分类 - vivian_ll
[13] Keras文本分类实战(上)- weixin_34351321
[14] 请问对于中文长文本分类,是CNN效果好,还是RNN效果好?- 知乎

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献5377条内容
已为社区贡献5377条内容

所有评论(0)